| Access Control
Sources (vsn) :
- Access & Usage Policies Enforcement (bv20)
- Access & Usage Policies Enforcement (bv30)
|
Systems and policies that regulate who can access specific data resources and under what conditions. |
| Accreditation
Sources (vsn) :
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
third-party attestation related to a conformity assessment body, conveying formal demonstration of its competence, impartiality and consistent operation in performing specific conformity assessment activities (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Accreditation Body
Source (vsn) : Trust Framework (bv30)
|
Authoritative body that performs accreditation (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Agreement
Source (vsn) : Contractual Framework (bv30)
|
A contract that states the rights and duties (obligations) of parties that have committed to (signed) it in the context of a particular data space. These rights and duties pertain to the data space and/or other such parties.
Note : This term was automatically generated as a synonym for: data-space-agreement
|
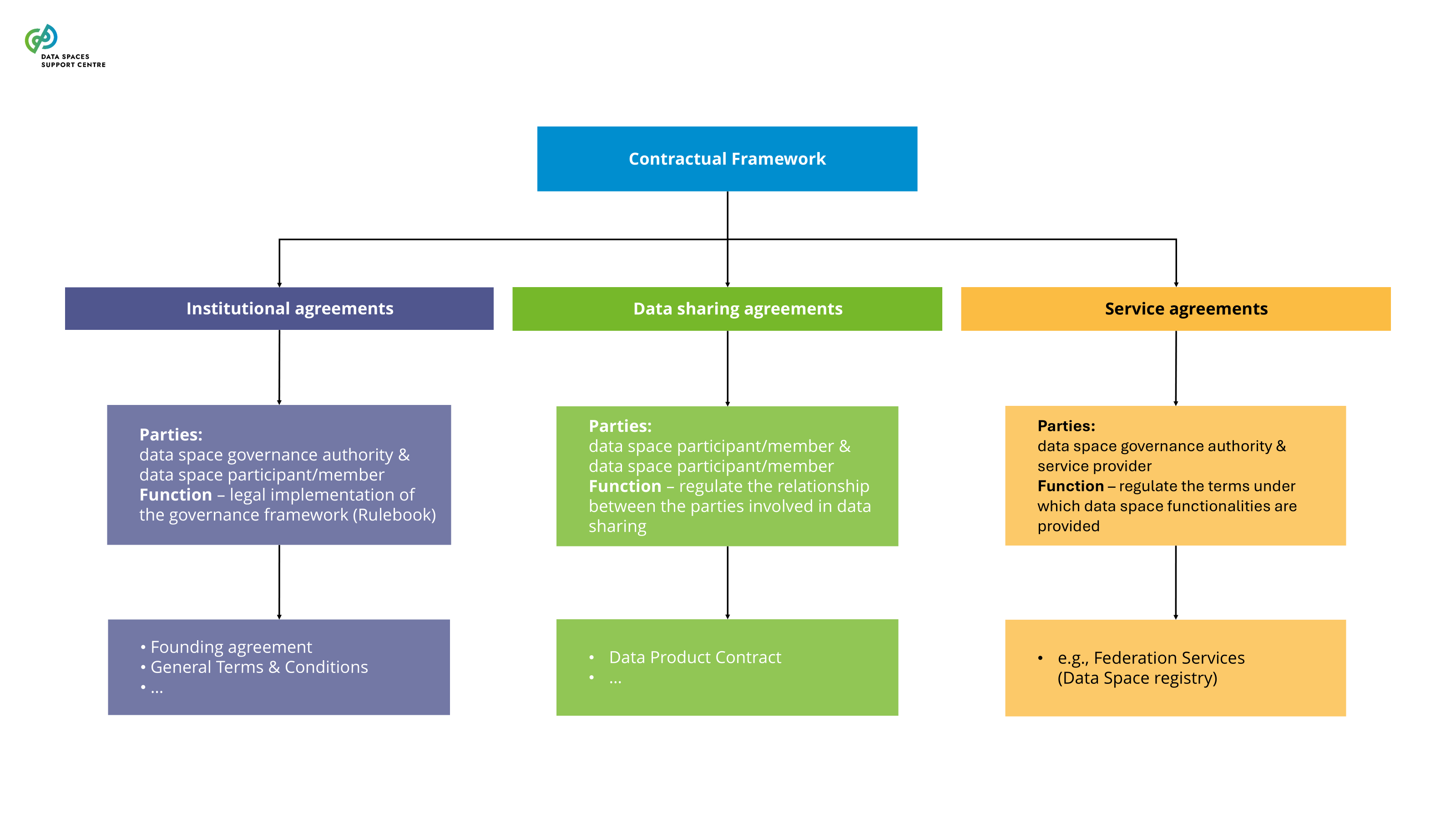
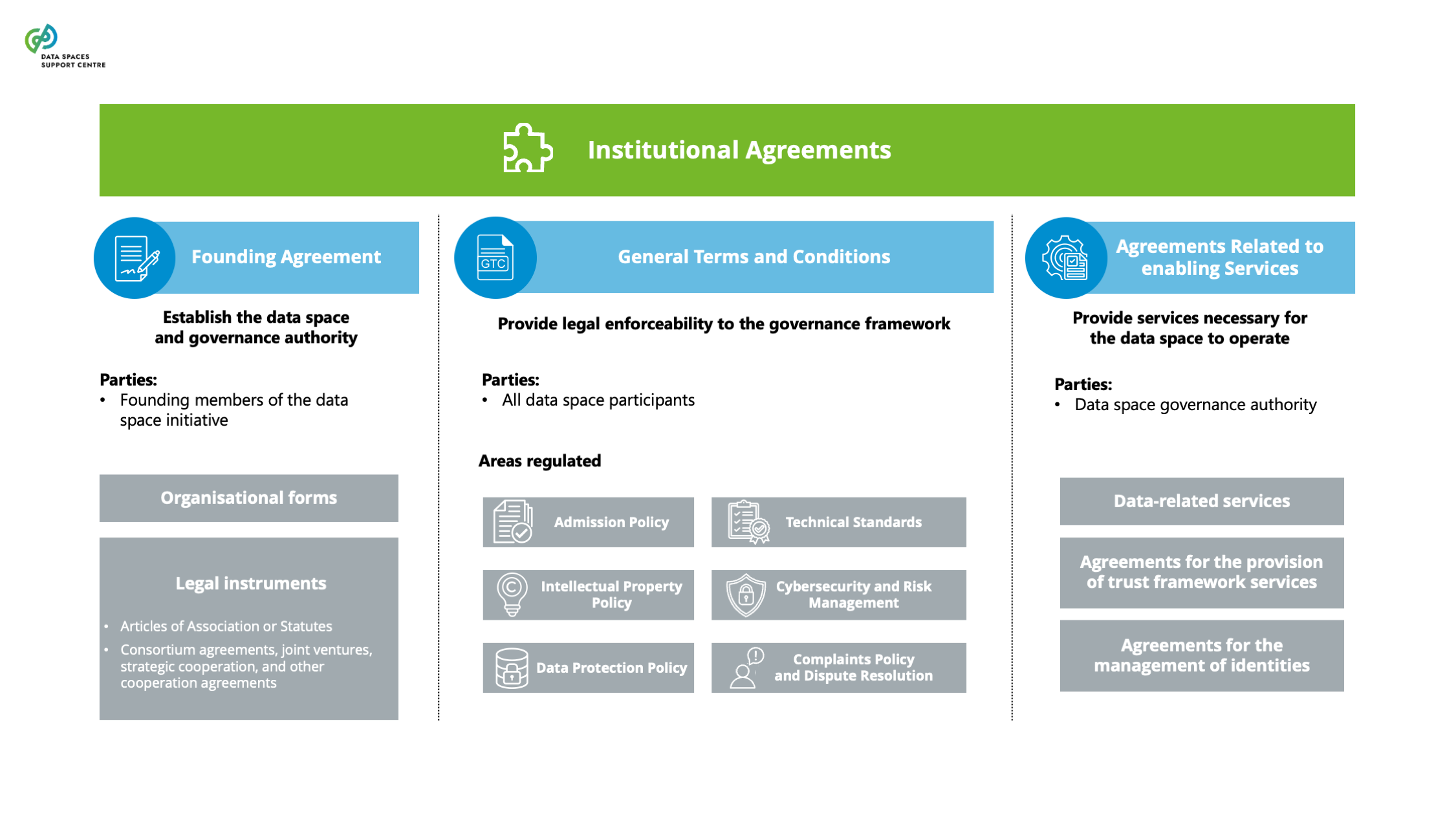
| Agreements Related To Enabling Services
Source (vsn) : Contractual Framework (bv20)
|
These agreements are entered into by the data space governance authority to provide the services necessary for the data space to operate. They can be classified as data-related services, agreements for the provision of trust framework services, and agreements for the management of identities. |
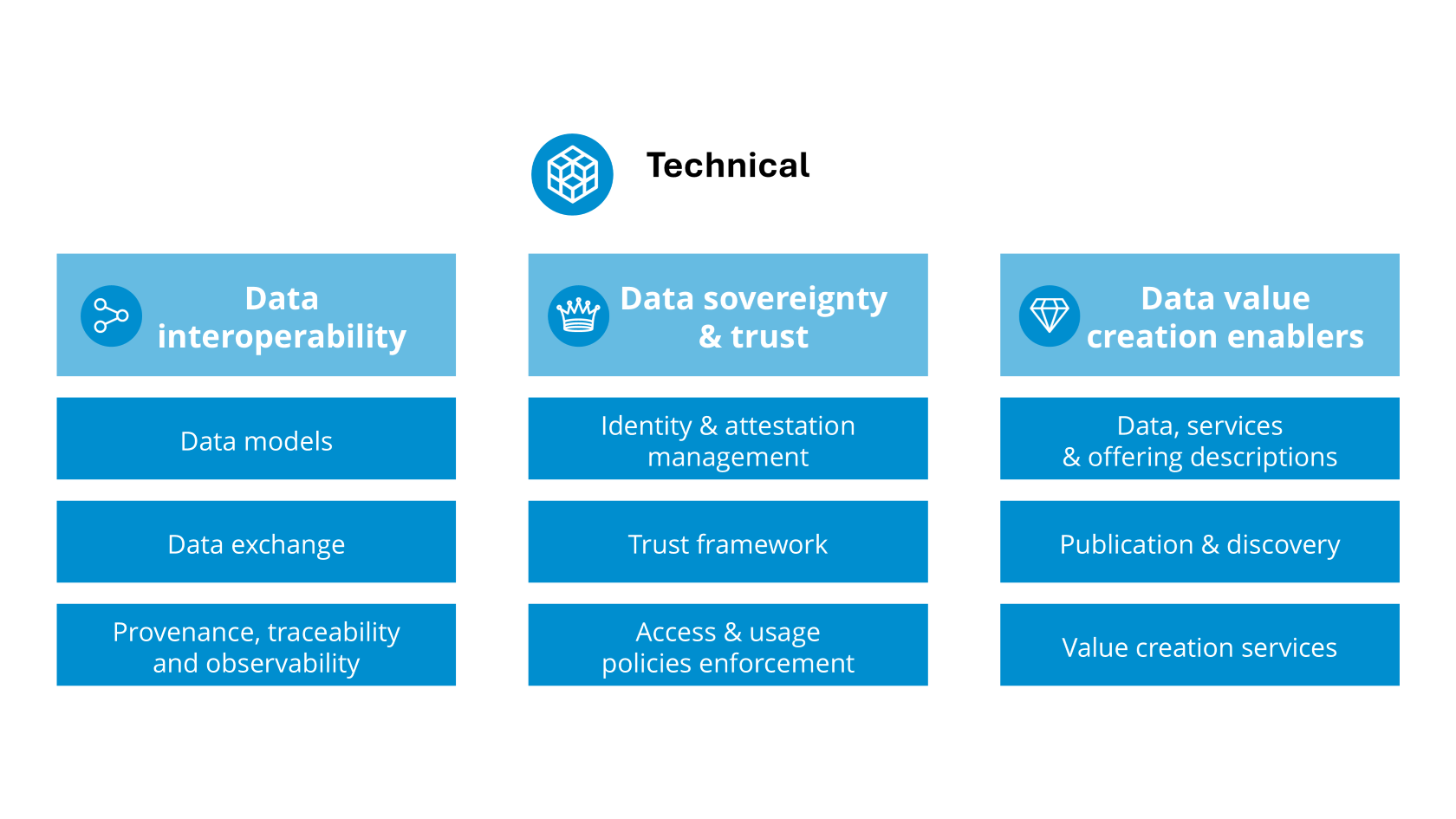
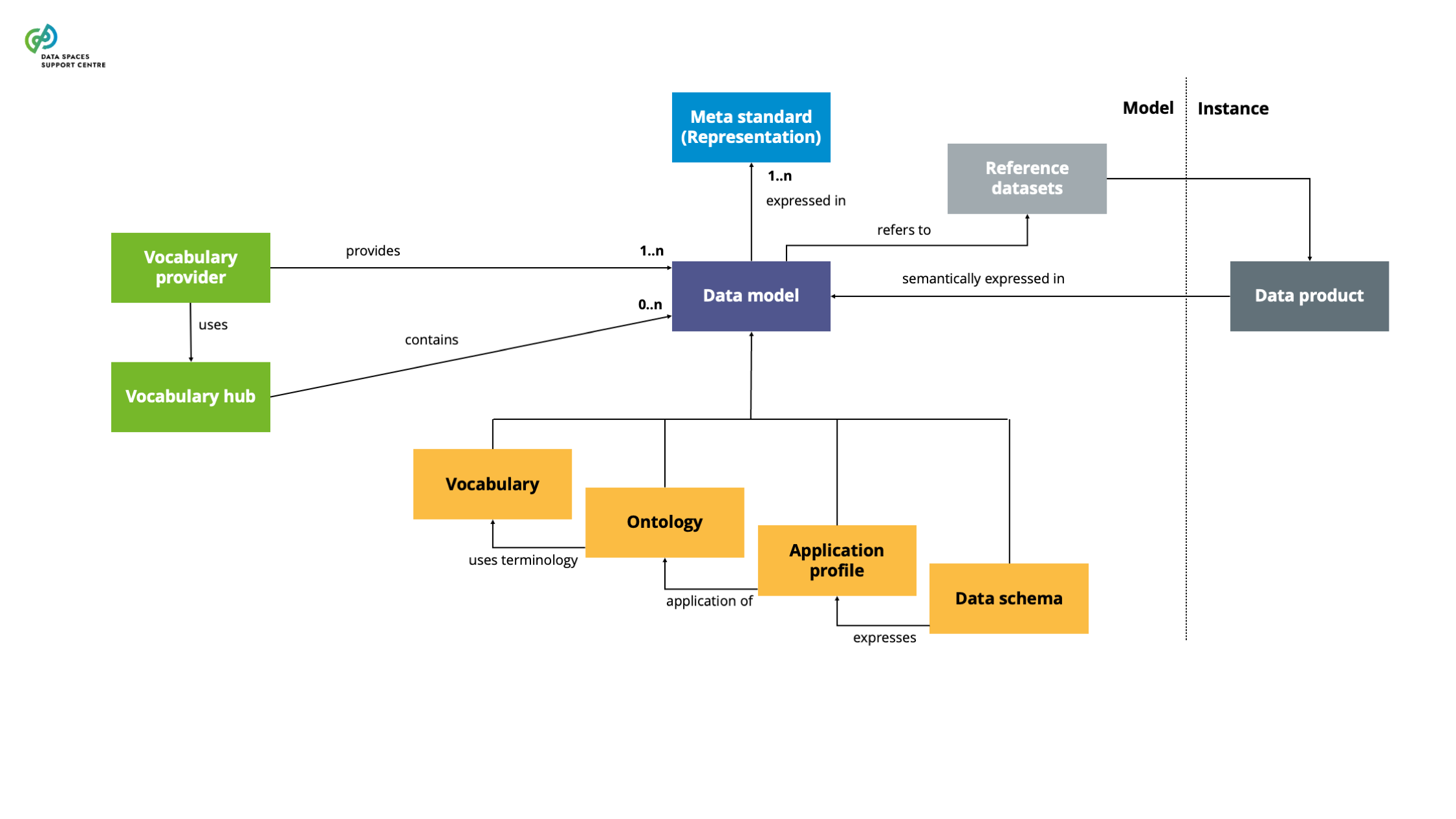
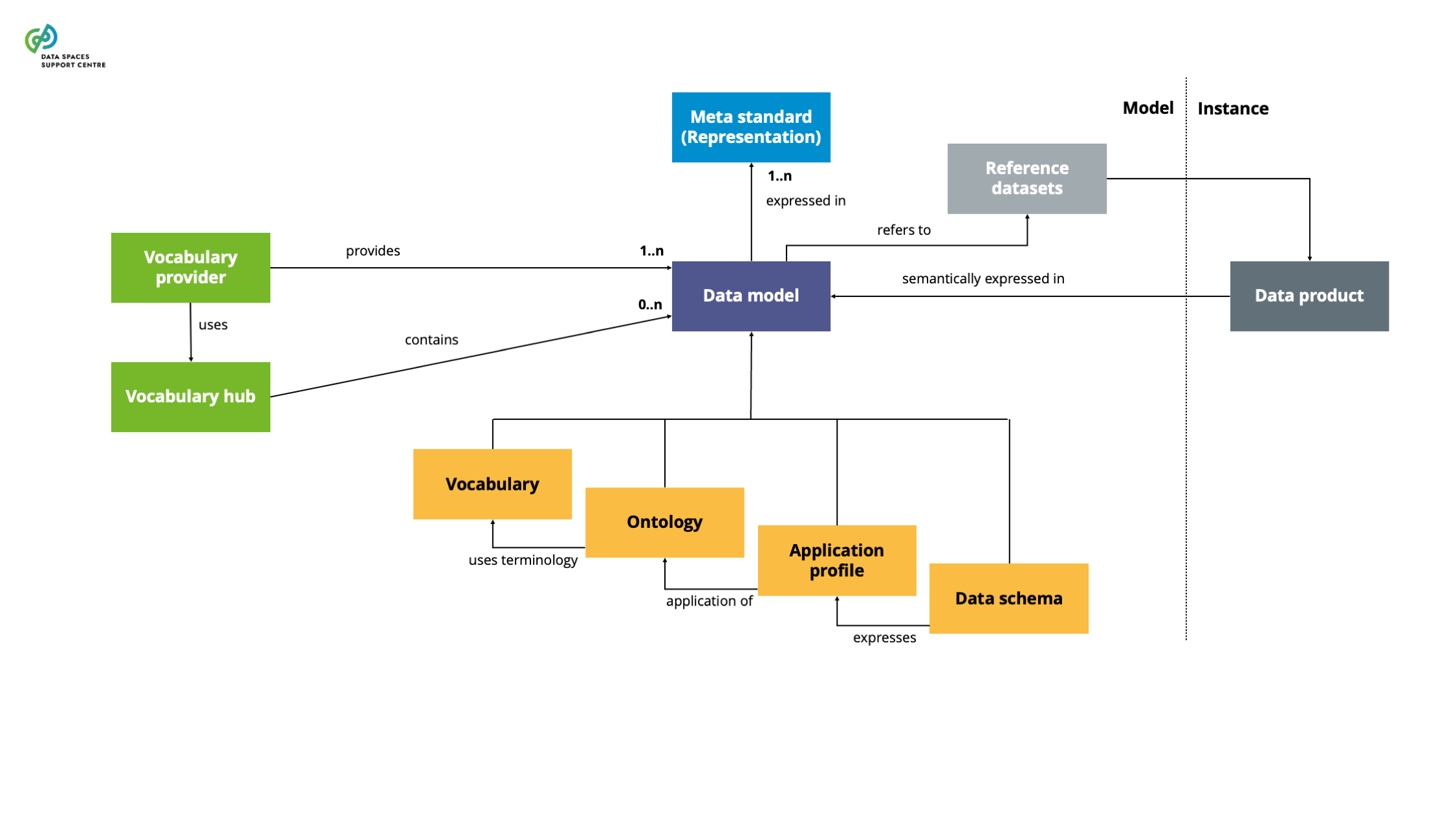
| Application Profile
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A data model that specifies the usage of information in a particular application or domain, often customised from existing data models (e.g., ontologies) to address specific application needs and domain requirements. |
| Assurance
Source (vsn) : 8 Identity and Trust (bv20)
|
An artefact that helps parties make trust decisions, such as certificates, commitments, contracts, warranties, etc. |
| Assurance
Source (vsn) : 8 Identity and Trust (bv30)
|
An artefact that helps parties make trust decisions about a claim, such as certificates, commitments, contracts, warranties, etc.
Explanatory Text : Also defined as: grounds for justified confidence that a claim has been or will be achieved [ISO/IEC/IEEE 15026-1:2019, 3.1.1]
|
| Attestation
Sources (vsn) :
- 8 Identity and Trust (bv30)
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
Issue of a statement, based on a decision, that fulfilment of specified requirements has been demonstrated (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Blueprint
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
A consistent, coherent and comprehensive set of guidelines to support the implementation, deployment and maintenance of data spaces.
Explanatory Text : The blueprint contains the conceptual model of data space, data space building blocks, and recommended selection of standards, specifications and reference implementations identified in the data spaces technology landscape.
Note : This term was automatically generated as a synonym for: data-spaces-blueprint
|
| Building Block
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
A description of related functionalities and/or capabilities that can be realised and combined with other building blocks to achieve the overall functionality of a data space.
Explanatory Texts :
- In the data space blueprint the building blocks are divided into organisational and business building blocks and technical building blocks.
- In many cases, the functionalities are implemented by Services
Note : This term was automatically generated as a synonym for: data-space-building-block
|
| Business Model
Source (vsn) : Business Model (bv30)
|
A description of the way an organisation creates, delivers, and captures value. Such a description typically includes for whom value is created (customer) and what the value proposition is.Typically, a tool called business model canvas is used to describe or design a business model, but alternatives that are more suitable for specific situations, such as data spaces, are available. |
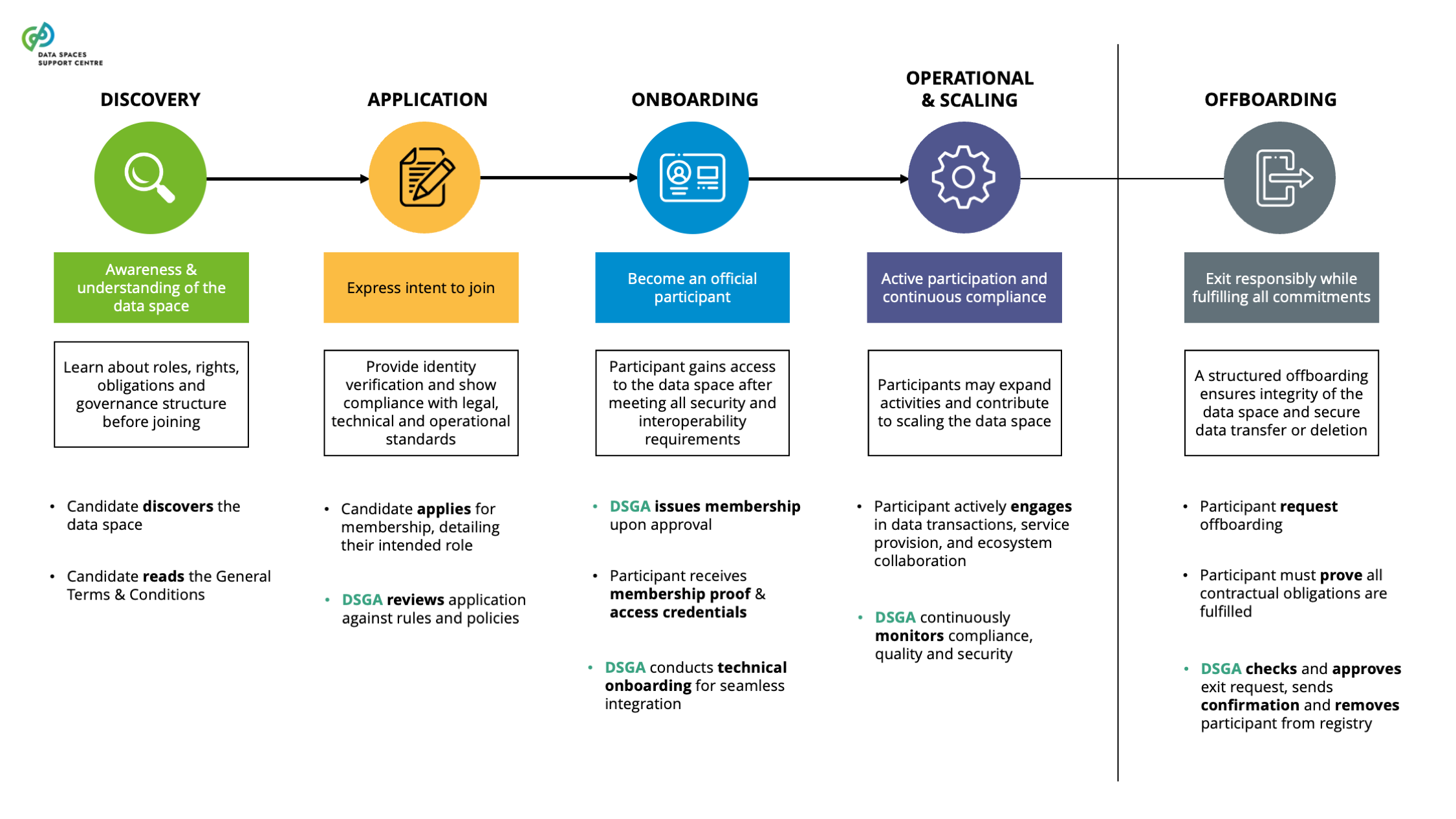
| Candidate
Source (vsn) : Participation Management (bv30)
|
A party interested in joining a data space as a participant. |
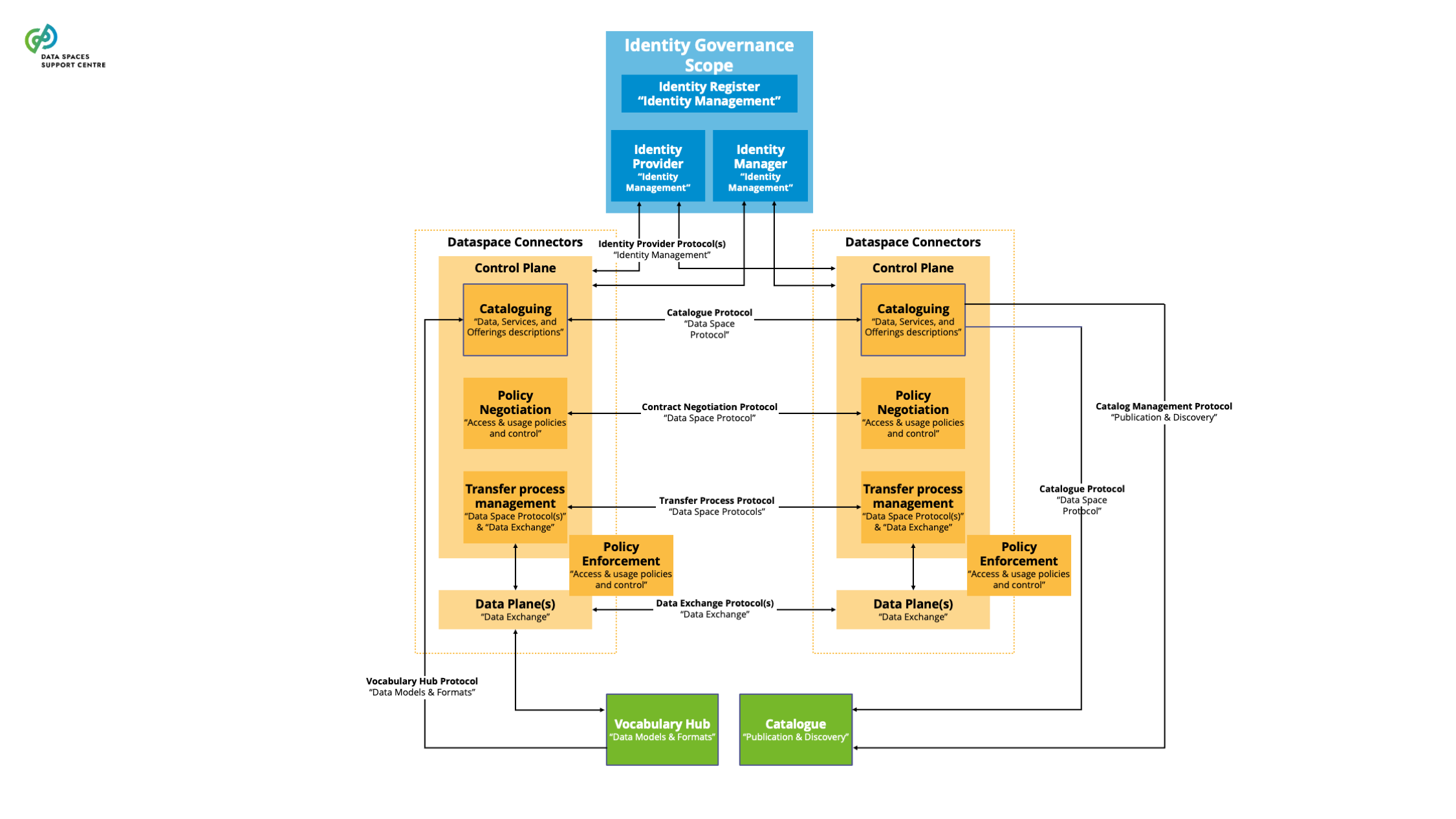
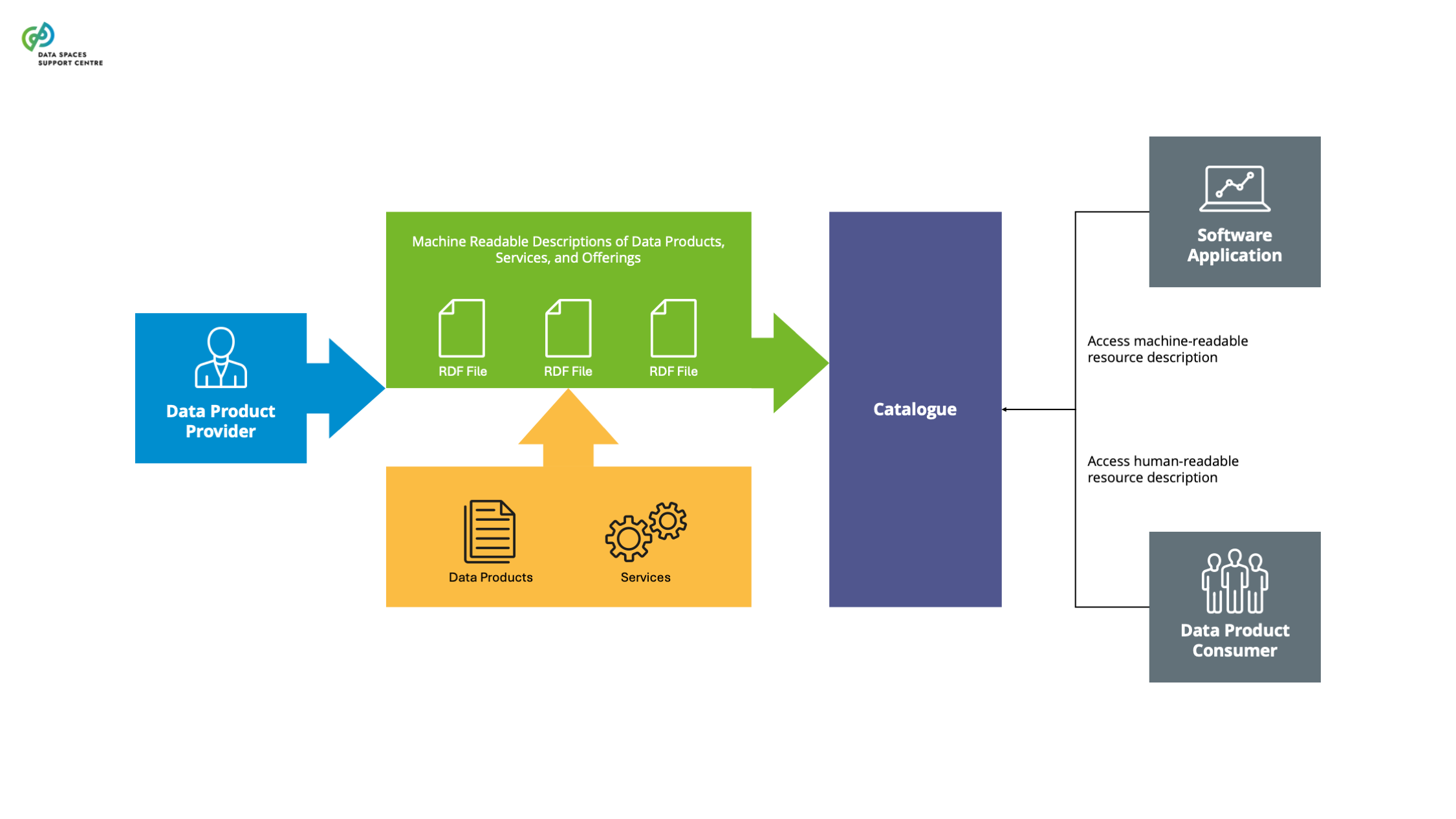
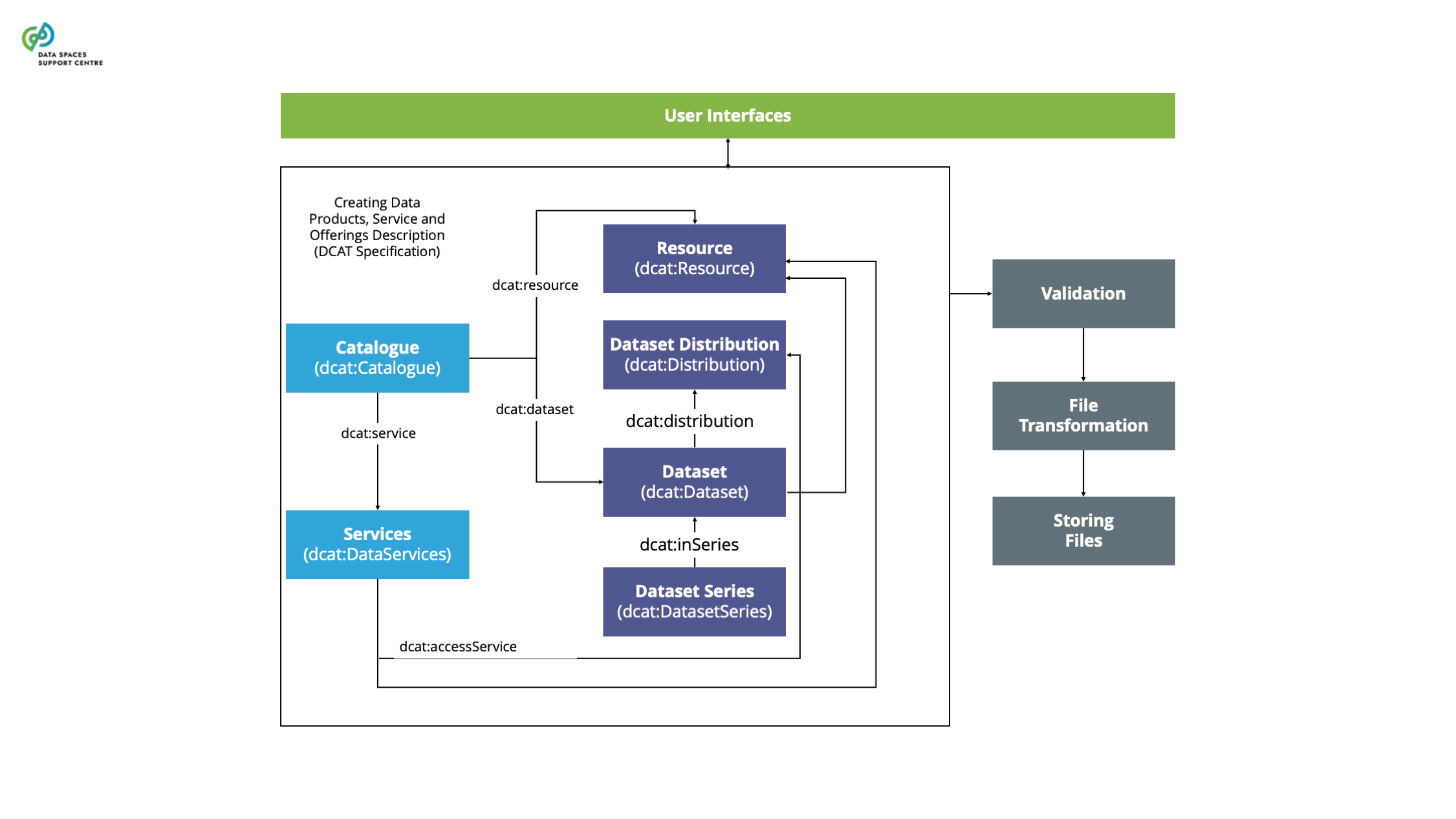
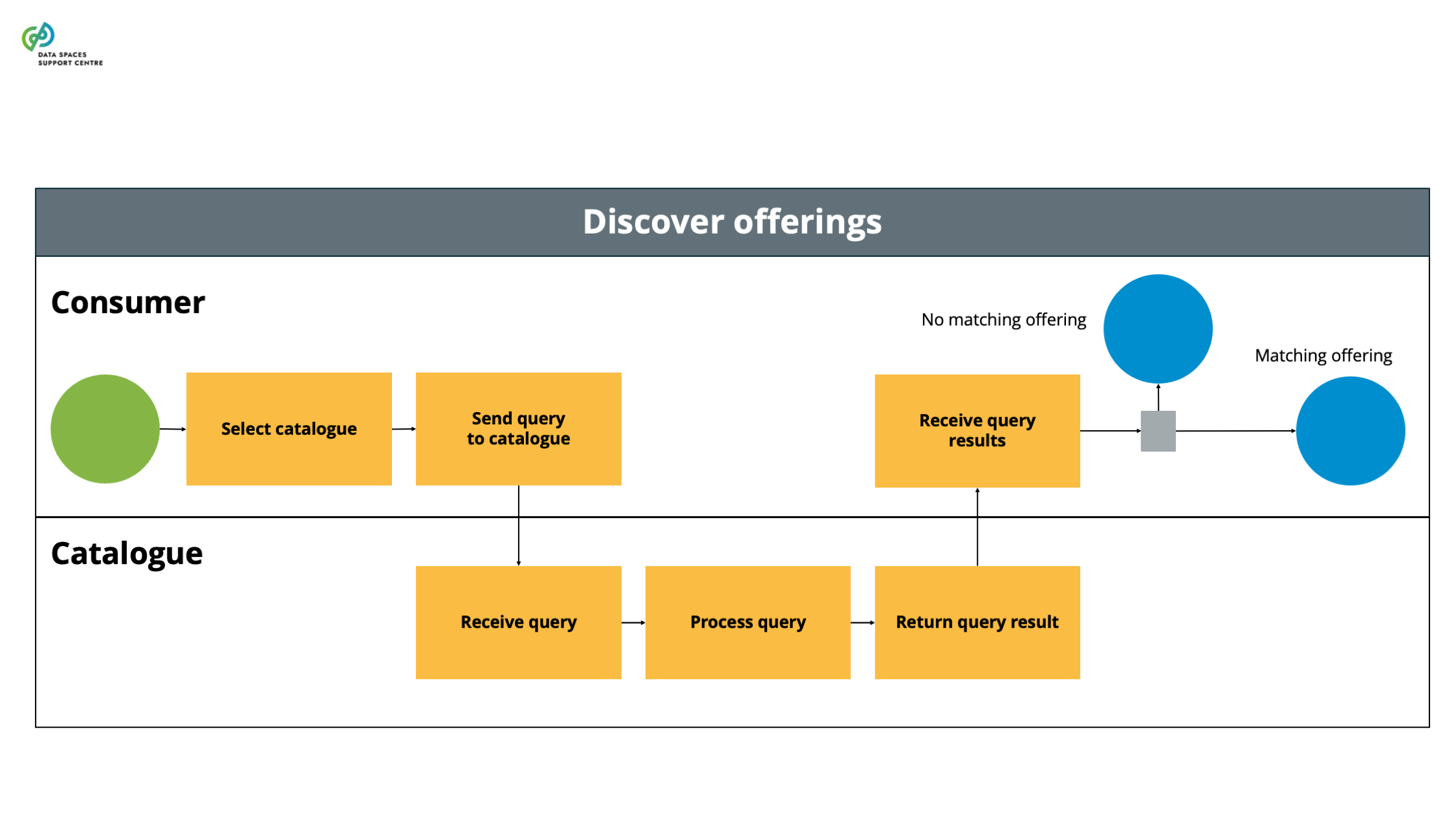
| Catalogue
Source (vsn) : Publication and Discovery (bv30)
|
A functional component to provision and discover offerings of data and services in a data space. |
| Certification
Source (vsn) : Identity & Attestation Management (bv30)
|
third-party attestation related to an object of conformity assessment, with the exception of accreditation (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Claim
Sources (vsn) :
- 8 Identity and Trust (bv30)
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
an assertion made about a subject . (ref. Verifiable Credentials Data Model v2.0 (w3.org) |
| Collaborative Business Model
Source (vsn) : Business Model (bv30)
|
A description of the way multiple organizations collectively create, deliver and capture value. Typically, this level of value creation would not be achievable by a single organization.A collaborative business model is better suited to express a value creation system consisting of multiple actors. Intangible values such as sovereignty, solidarity, and security cannot be expressed through a transactional approach (which is common in firm-centric business models) but require a system perspective. |
| Common European Data Spaces
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
Sectoral/domain-specific data spaces established in the European single market with a clear EU-wide scope that adheres to European rules and values.
Explanatory Texts :
- Common European Data Spaces are mentioned in the EU data strategy and introduced in the EC Staff Working Document on Common European Data Spaces and on this site: https://digital-strategy.ec.europa.eu/en/policies/data-spaces.
- It is furthermore referenced in the Data Governance Act with the following description: Purpose-, sector-specific or cross-sectoral interoperable frameworks of common standards and practices to share or jointly process data for, inter alia, development of new products and services, scientific research or civil society initiatives.
- Such sectoral/domain-specific Common European Data Spaces are being supported through EU-funding programmes, e.g. DIGITAL, Horizon Europe. In some domains (Health, Procurement) specific regulations towards the establishment of such data spaces are forthcoming.
|
| Community Heartbeat
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
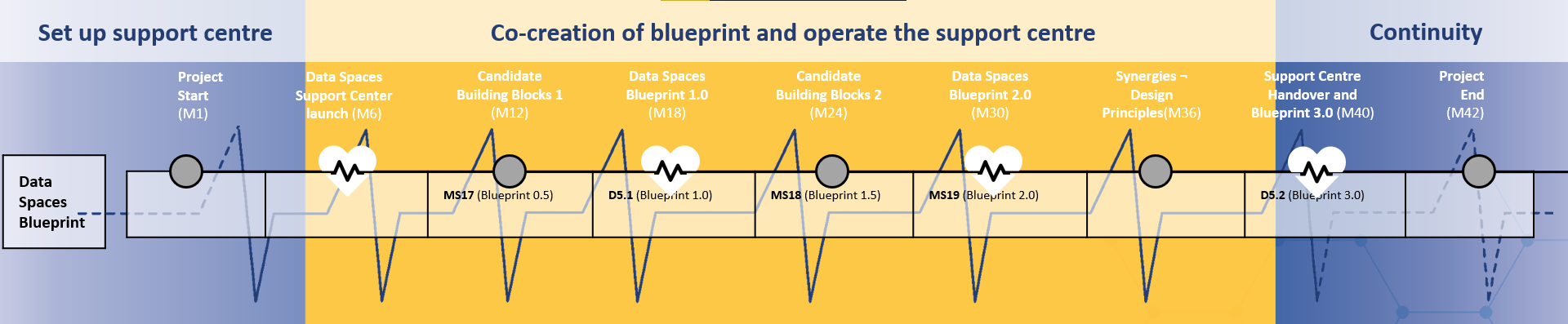
The regular release of the data spaces blueprint, data spaces building blocks, other DSSC assets and supporting activities, as outlined in a public roadmap. The regular releases aim to engage the community of practice into a rhythm of communication, co-learning and continuous improvement. |
| Community Of Practice
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
The set of existing and emerging data space initiatives in all sectors and the set of (potential) data space component implementers. DSSC prioritises the data space projects funded by the Digital Europe Programme and other relevant programmes and will later expand to additional data space initiatives. |
| Compliance Service
Source (vsn) : Identity & Attestation Management (bv30)
|
Service taking as input the Verifiable Credentials provided by the participants, checking them against the SHACL Shapes available in the Data Space Registry and performing other consistency checks based on rules in the data space conformity assessment scheme. |
| Component
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
A specification for a software or other artefact that realises one service or a set of services that fulfil functionalities described by one or more building blocks.
Explanatory Text : For technical components, that would typically be software, but for business components, this could consist of processes, templates or other artefacts.
Note : This term was automatically generated as a synonym for: data-space-component
|
| Component Architecture
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
An overview of all the data space components and their interactions, providing a high-level structure of how these components are organised and interact within data spaces.
Note : This term was automatically generated as a synonym for: data-space-component-architecture
|
| Conceptual Model Of Data Space
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A consistent, coherent and comprehensive description of the concepts and their relationships that can be used to unambiguously explain what data spaces and data space initiatives are about. |
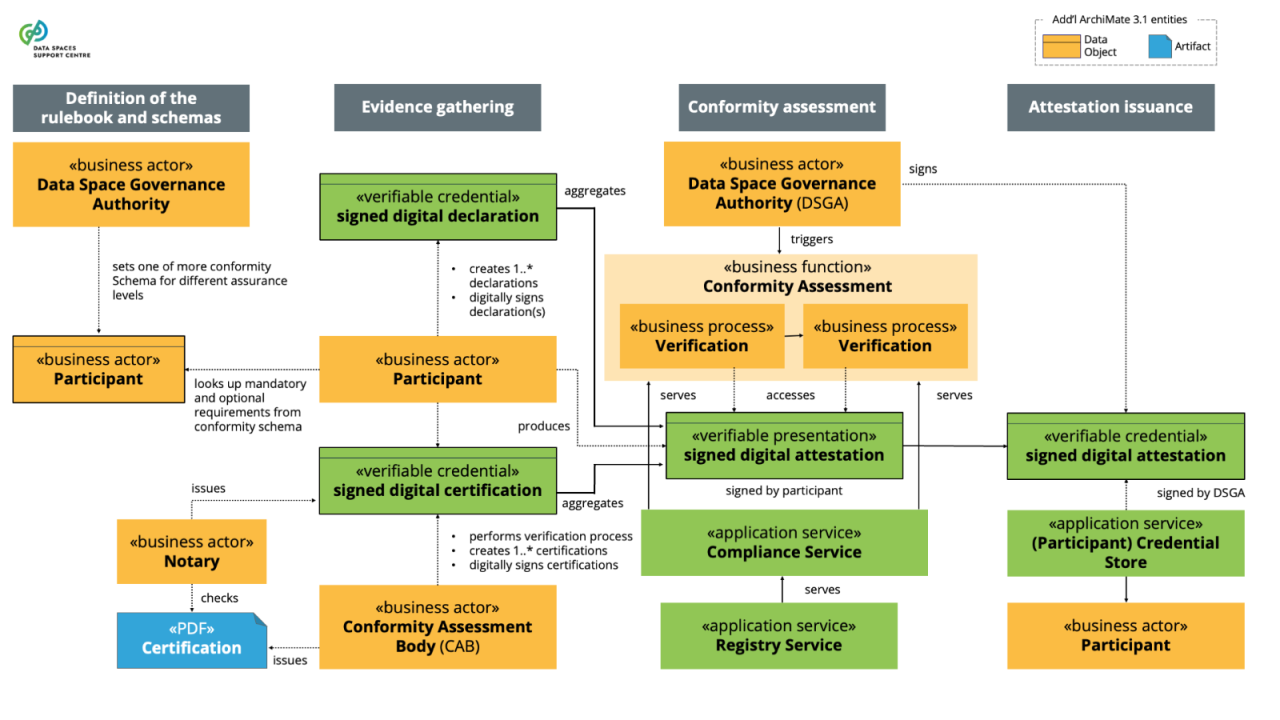
| Conformity Assessment
Source (vsn) : Identity & Attestation Management (bv30)
|
demonstration that specified requirements are fulfilled (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Conformity Assessment Body
Sources (vsn) :
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
A body that performs conformity assessment activities, excluding accreditation (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Conformity Assessment Scheme
Source (vsn) : Identity & Attestation Management (bv30)
|
set of rules and procedures that describe the objects of conformity assessment, identifies the specified requirements and provides the methodology for performing conformity assessment. (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ). |
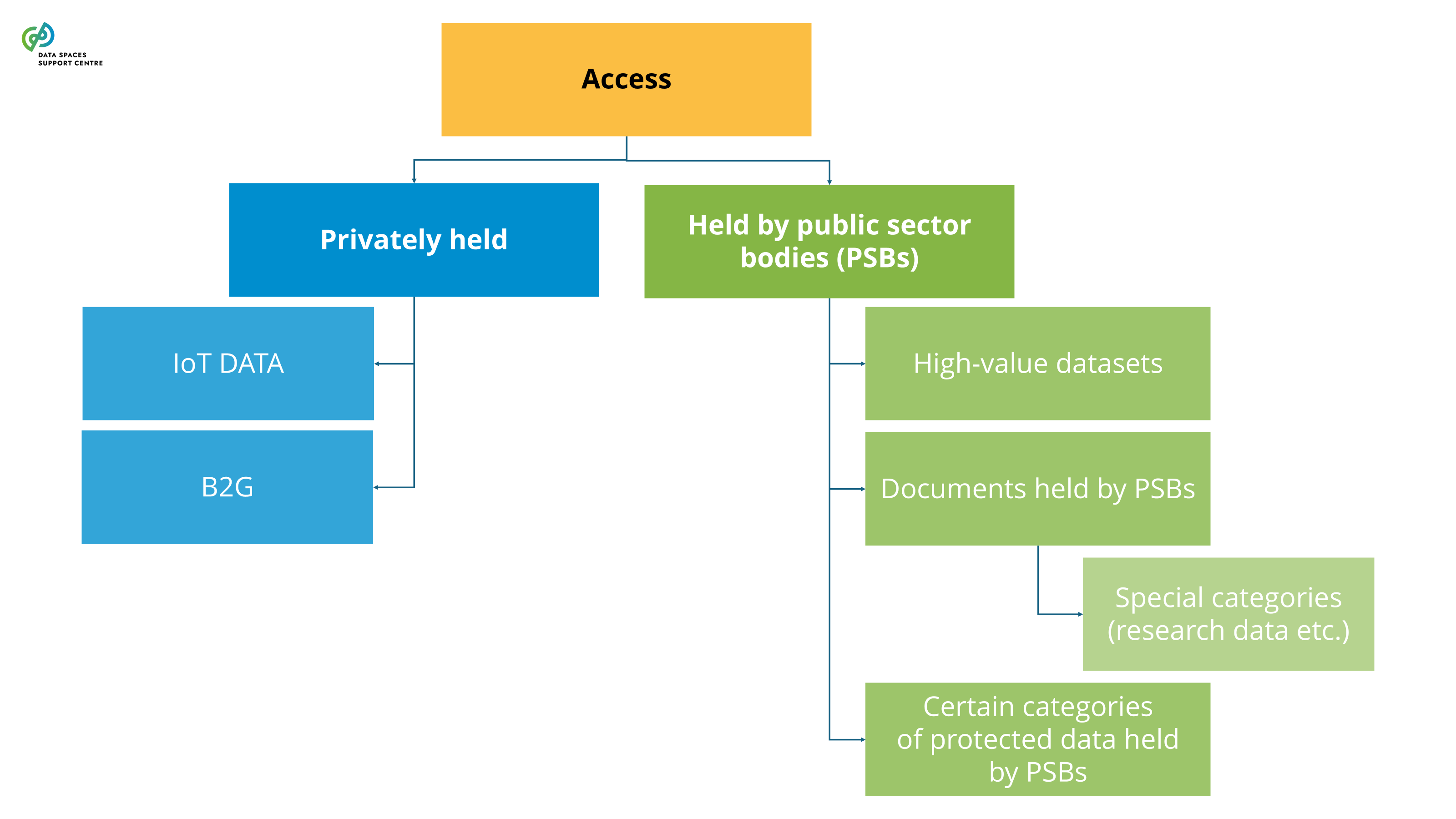
| Connected Product
Source (vsn) : Regulatory Compliance (bv20)
|
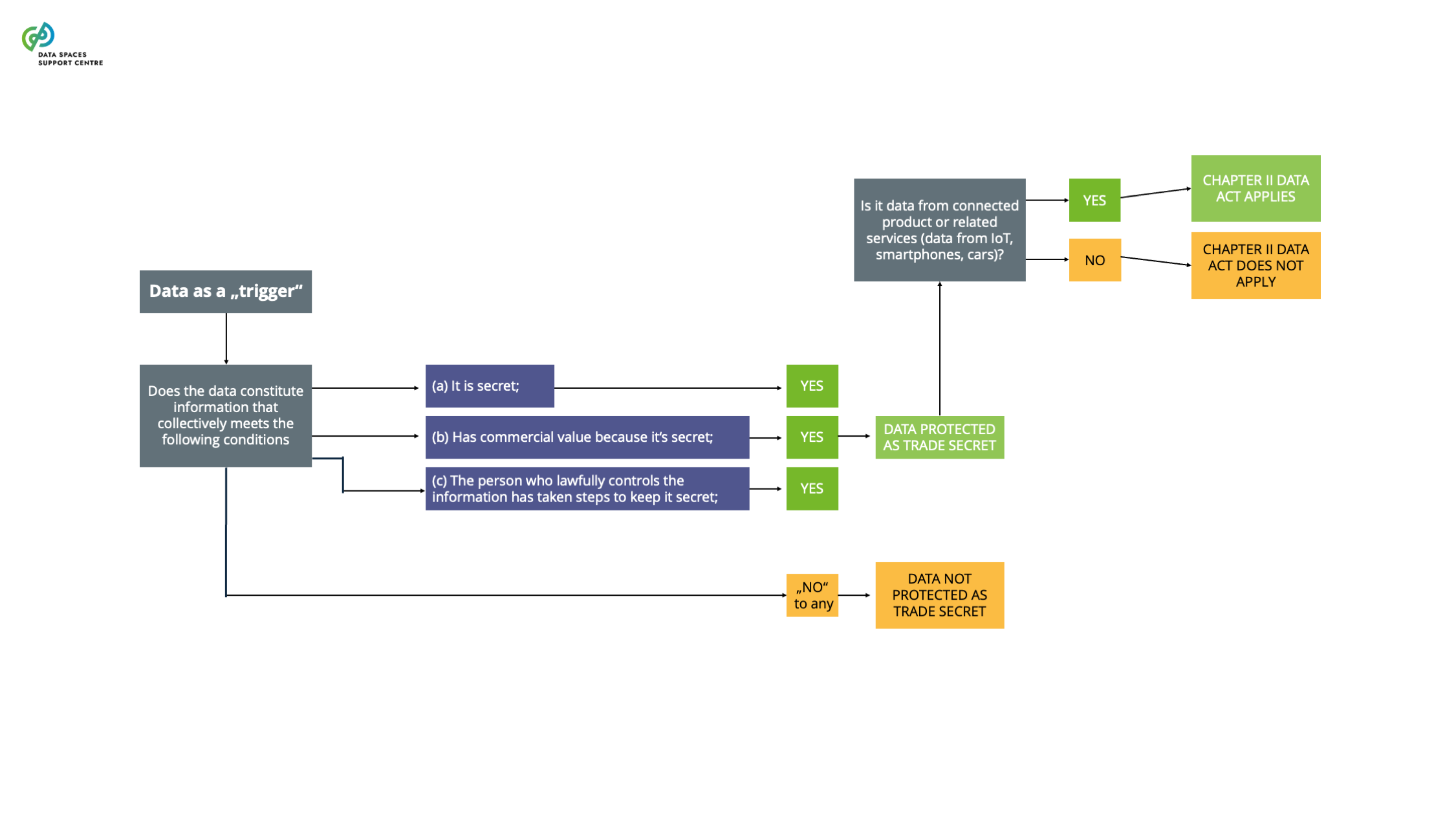
an item that obtains, generates or collects data concerning its use or environment and that is able to communicate product data via an electronic communications service, physical connection or on-device access, and whose primary function is not the storing, processing or transmission of data on behalf of any party other than the user (art. 2 (5) DA).
Explanatory Text : This term is defined as per the Data Act. This clarification ensures that the definition is understood within the specific regulatory context of the Data Act while allowing the same term to be used in other contexts with different meanings.
|
| Connector
Source (vsn) : 4 Data Space Services (bv20)
|
A technical component that is run by (or on behalf of) a participant and that provides participant agent services, with similar components run by (or on behalf of) other participants.
Explanatory Text : A connector can provide more functionality than is strictly related to connectivity. The connector can offer technical modules that implement data interoperability functions, authentication interfacing with trust services and authorisation, data product self-description, contract negotiation, etc. We use “participant agent services” as the broader term to define these services.
Note : This term was automatically generated as a synonym for: data-space-connector
|
| Consensus Protocol
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
The data exchange protocol that is globally accepted in a domain
Explanatory Text : In some domains the data exchange protocols are ‘de facto’ standards (e.g. NGSI for smart cities).
|
| Consent
Source (vsn) : Regulatory Compliance (bv20)
|
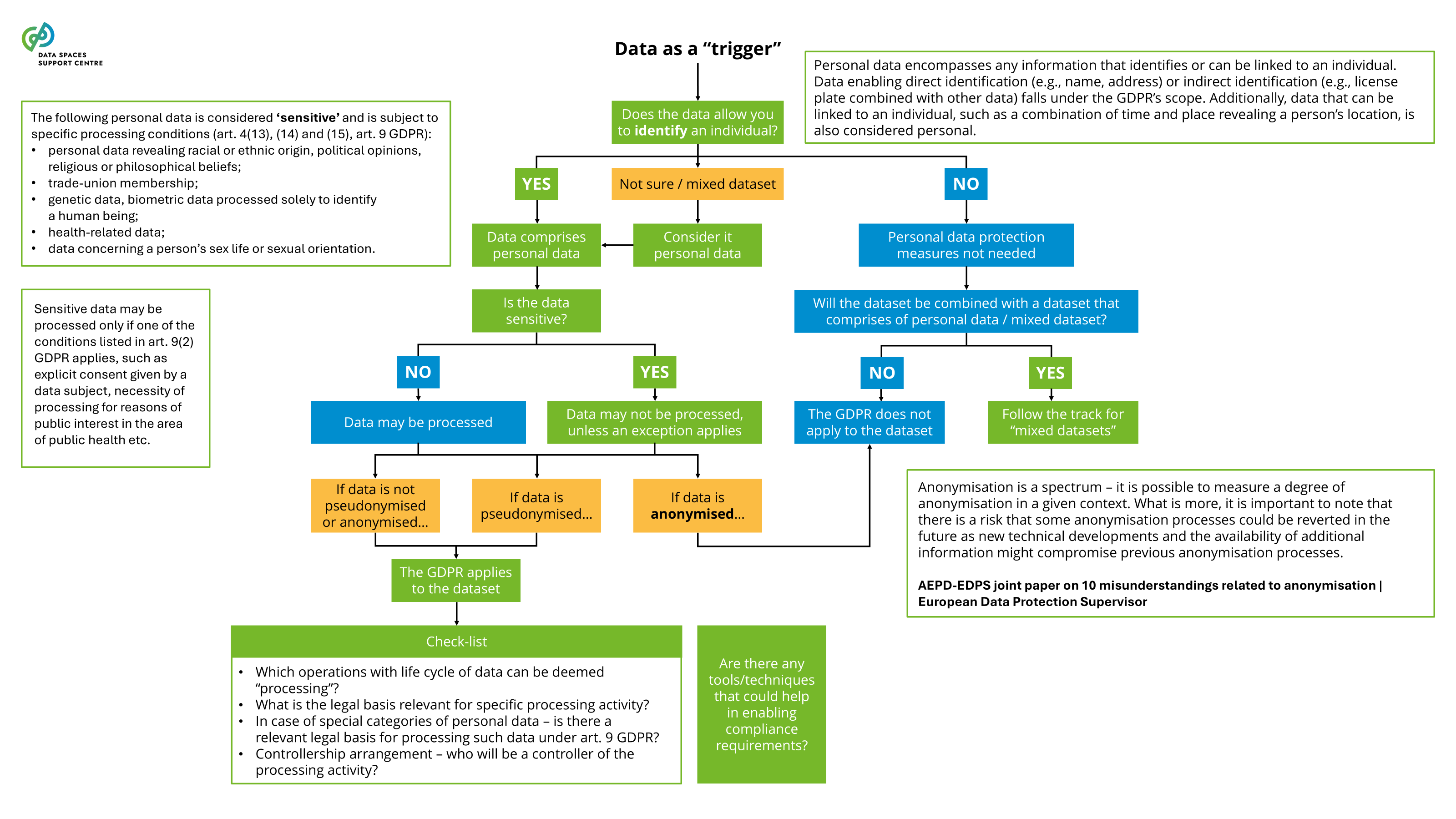
any freely given, specific, informed and unambiguous indication of the data subject's wishes by which he or she, by a statement or by a clear affirmative action, signifies agreement to the processing of personal data relating to him or her;( GDPR Article 4(11) ) |
| Consent Management
Source (vsn) : Access & Usage Policies Enforcement (bv20)
|
The process of obtaining, recording, managing, and enforcing user consent for data processing and sharing. |
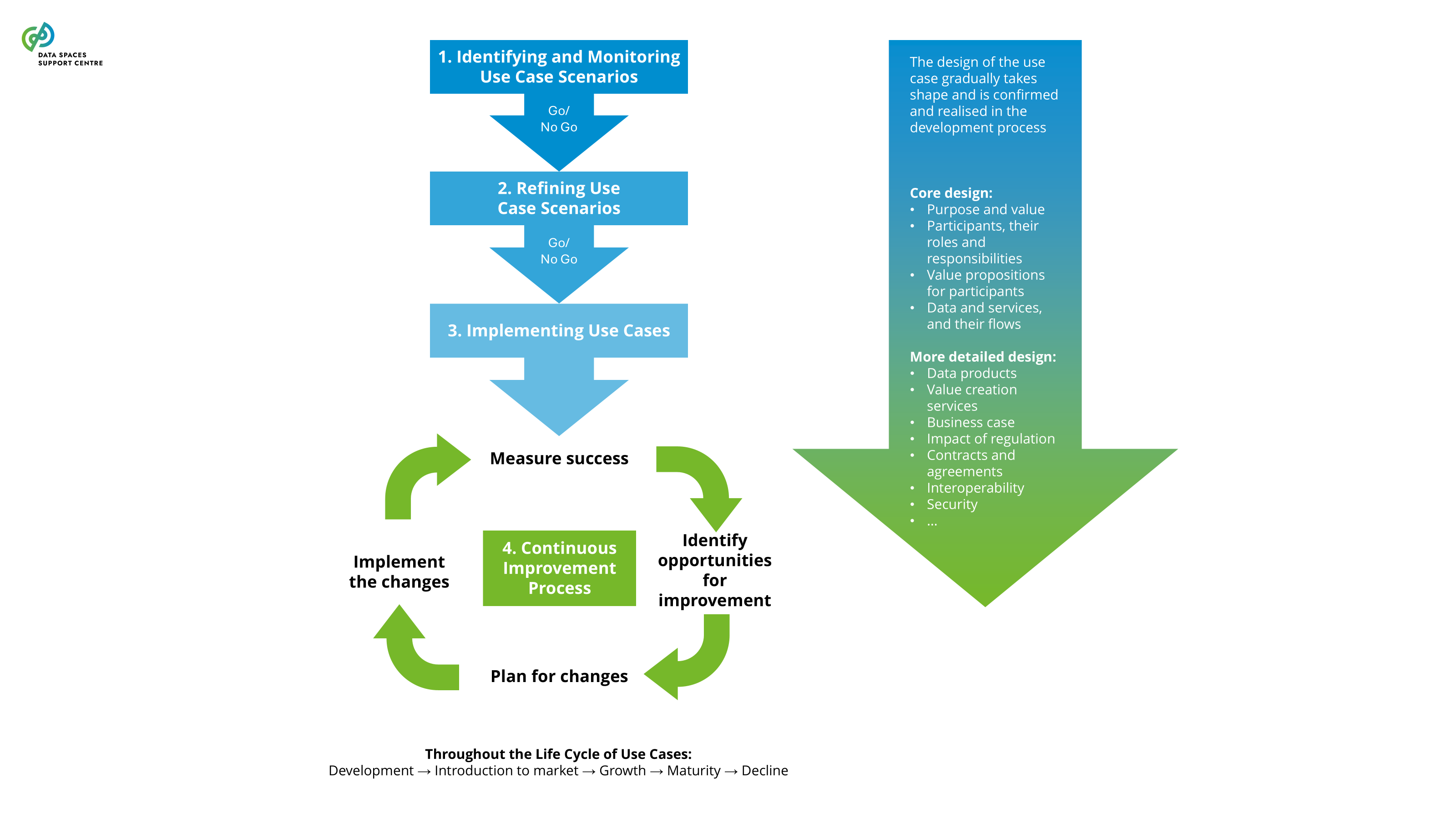
| Continuous Improvement Process
Sources (vsn) :
- Use Case Development (bv20)
- Use Case Development (bv30)
|
Continuously analyzing the performance of use cases, identifying improvement opportunities, and planning and implementing changes in a systematic and managed way throughout the life cycle of a use case. |
| Contract
Source (vsn) : Contractual Framework (bv30)
|
A formal, legally binding agreement between two or more parties with a common interest in mind that creates mutual rights and obligations enforceable by law. |
| Contractual Framework
Source (vsn) : Contractual Framework (bv30)
|
The set of legally binding agreements that regulates the relationship between data space participants and the data space (institutional agreements), transactions between data space participants (data-sharing agreements) and the provision of services (service agreements) within the context of a single data space. |
| Core Platform Service
Source (vsn) : Regulatory Compliance (bv20)
|
a service that means any of the following:
online intermediation services; online search engines; online social networking services; video-sharing platform services; number-independent interpersonal communications services; (f) operating systems;web browsers; virtual assistants; cloud computing services; online advertising services, including any advertising networks, advertising exchanges and any other advertising intermediation services, provided by an undertaking that provides any of the core platform services listed in points (1) to (9);
|
| Credential Schema
Source (vsn) : Identity & Attestation Management (bv30)
|
In the W3C Verifiable Credentials Data Model v2.0. the value of the “credentialSchema” property must be one or more data schemas that provide verifiers with enough information to determine whether the provided data conforms to the provided schema(s). (ref: https://www.w3.org/TR/vc-data-model-2.0/#data-schemas ) |
| Credential Store
Source (vsn) : Identity & Attestation Management (bv30)
|
A service used to issue, store, manage, and present Verifiable Credentials. |
| Cross Data Space Use Case
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
A specific setting in which participants of multiple data spaces create value (business, societal or environmental) from sharing data across these data spaces. |
| Cross Use Case
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
A specific setting in which participants of multiple data spaces create value (business, societal or environmental) from sharing data across these data spaces.
Note : This term was automatically generated as a synonym for: cross-data-space-use-case
|
| Cross- Interoperability
Source (vsn) : 7 Interoperability (bv30)
|
The ability of participants to seamlessly access and/or exchange data across two or more data spaces. Cross-data spaces interoperability addresses the governance, business and technical frameworks to interconnect multiple data space instances seamlessly.
Explanatory Text : Inter-data space interoperability is an alternative term and both terms can be used interchangeably.
Note : This term was automatically generated as a synonym for: cross-data-space-interoperability
|
| Cross-data Space Interoperability
Source (vsn) : 7 Interoperability (bv30)
|
The ability of participants to seamlessly access and/or exchange data across two or more data spaces. Cross-data spaces interoperability addresses the governance, business and technical frameworks to interconnect multiple data space instances seamlessly.
Explanatory Text : Inter-data space interoperability is an alternative term and both terms can be used interchangeably.
|
| Data
Source (vsn) : Regulatory Compliance (bv20)
|
any digital representation of acts, facts or information and any compilation of such acts, facts or information, including in the form of sound, visual or audiovisual recording;( DGA Article 2(1) )
Explanatory Text : The definition is the same in the Open Data Directive and the Data Act.
|
| Data Access Policy
Source (vsn) : 6 Data Policies and Contracts (bv30)
|
A specific data policy defined by the data rights holder for accessing their shared data in a data space.
Explanatory Text : A data access policy that provides operational guidance to a data provider for deciding whether to process or reject a request for providing access to specific data. Data access policies are created and maintained by the data rights holders.
|
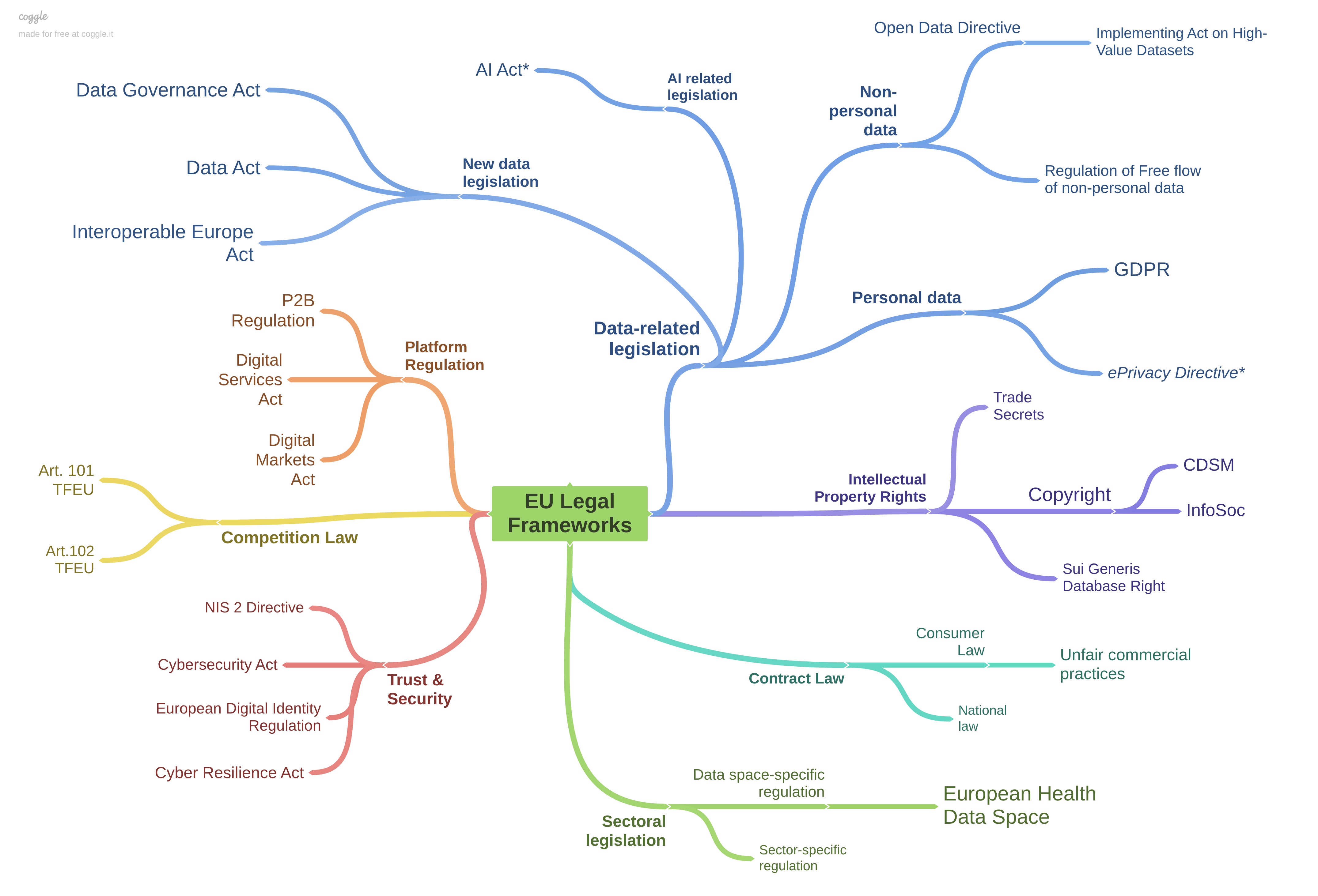
| Data Act
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
A European regulation that establishes EU-wide rules for access to the product or related service data to the user of that connected product or service. The regulation also includes essential requirements for the interoperability of data spaces (Article 33) and essential requirements for smart contracts to implement data sharing agreements (Article 36).
Explanatory Text : More info can be found here: Data Act explained | Shaping Europe’s digital future and the Data Act Frequently-asked-questions.
|
| Data Altruism
Source (vsn) : Regulatory Compliance (bv20)
|
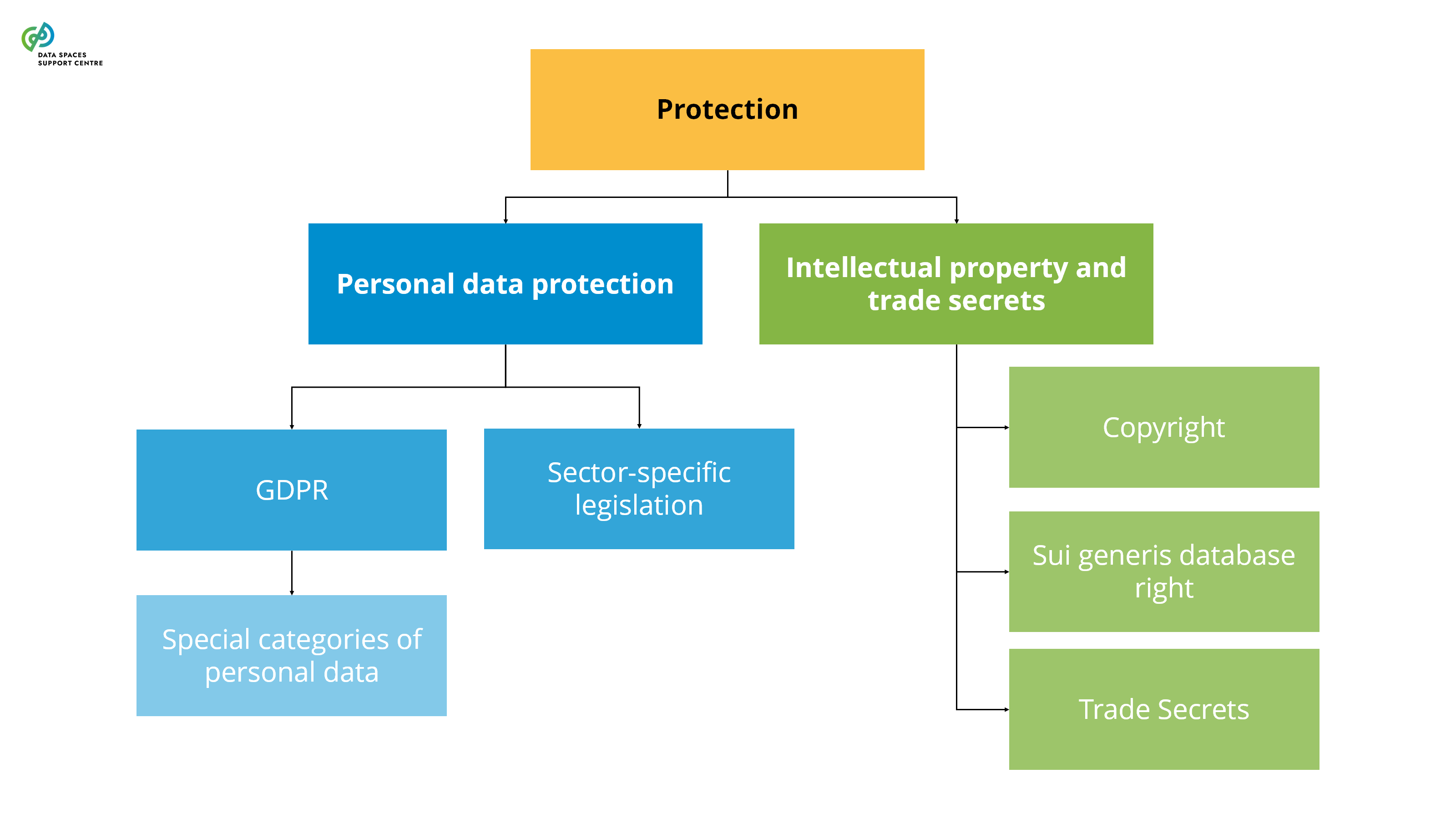
the voluntary sharing of data on the basis of the consent of data subjects to process personal data pertaining to them, or permissions of data holders to allow the use of their non-personal data without seeking or receiving a reward that goes beyond compensation related to the costs that they incur where they make their data available for objectives of general interest as provided for in national law, where applicable, such as healthcare, combating climate change, improving mobility, facilitating the development, production and dissemination of official statistics, improving the provision of public services, public policy making or scientific research purposes in the general interest;( DGA Article 2(16) ) |
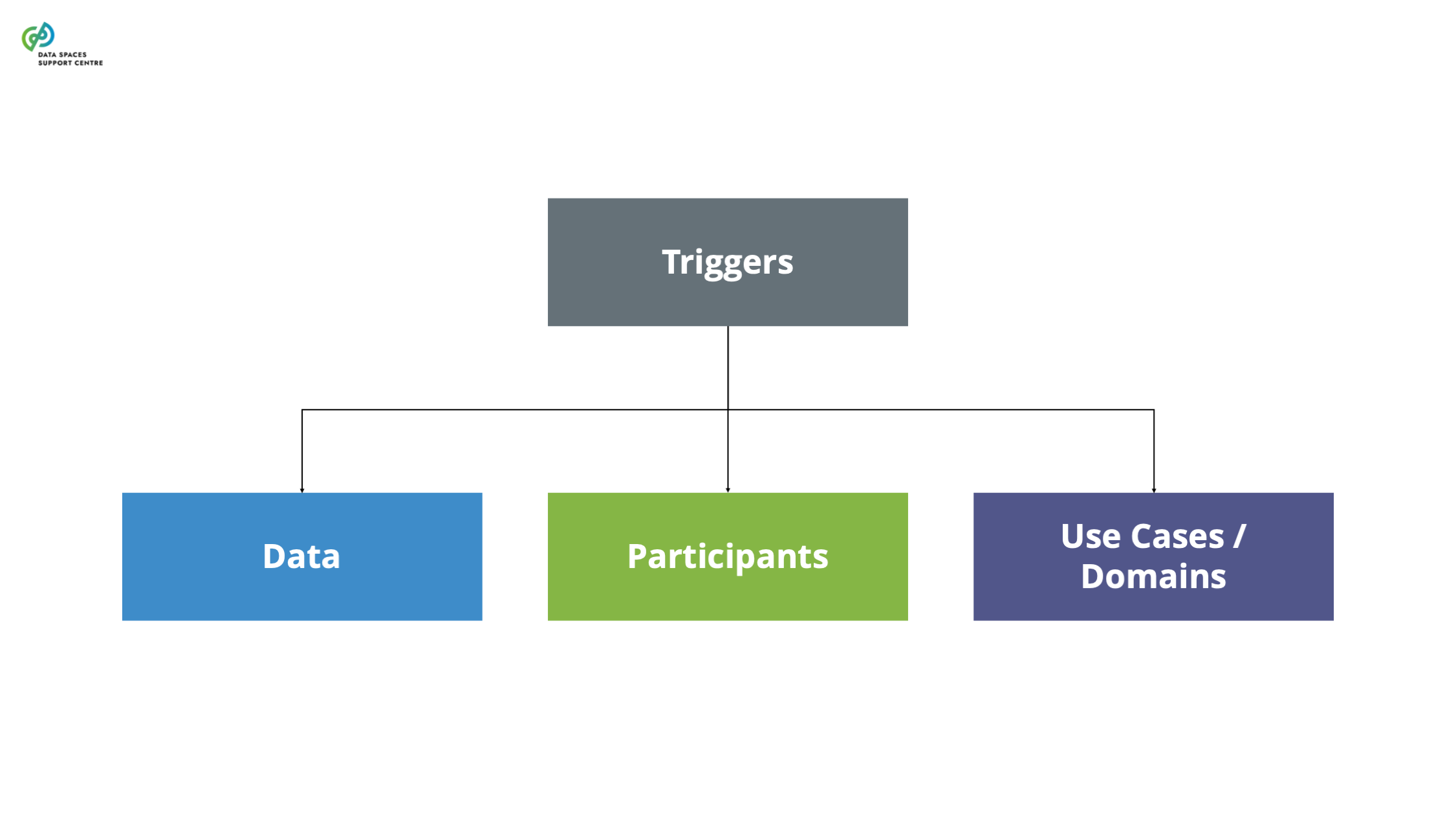
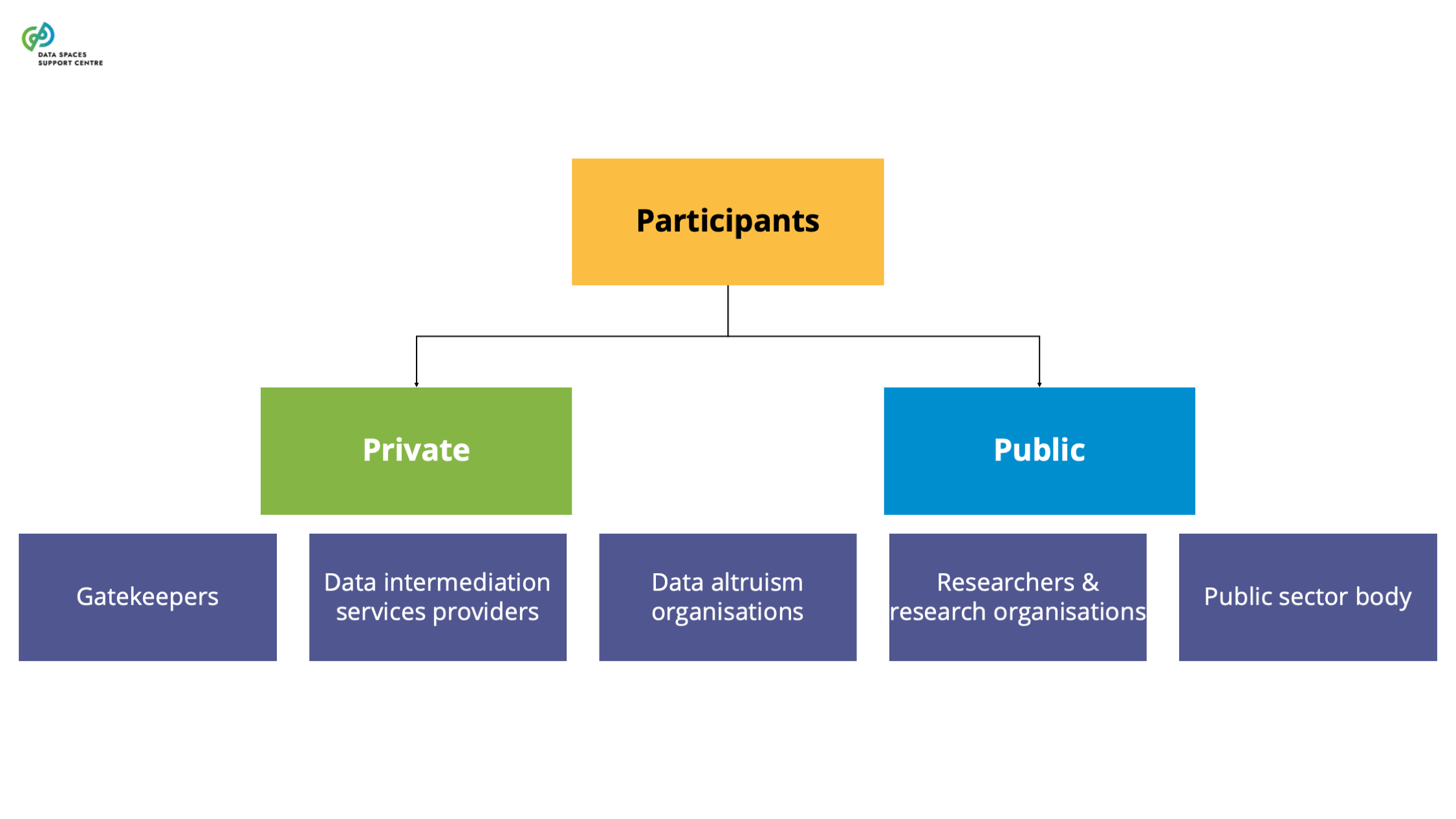
| Data Altruism Organisations (DAOs)
Source (vsn) : Types of Participants (Participant as a Trigger) (bv20)
|
In the context of data spaces, DAOs can take on a variety of roles as data space participants. They can be data providers, transaction participants, and data space intermediaries (e.g., personal data intermediaries). It is important to address their participation in the data space, especially regarding the value distribution aspects and their potential sponsoring by the data space . |
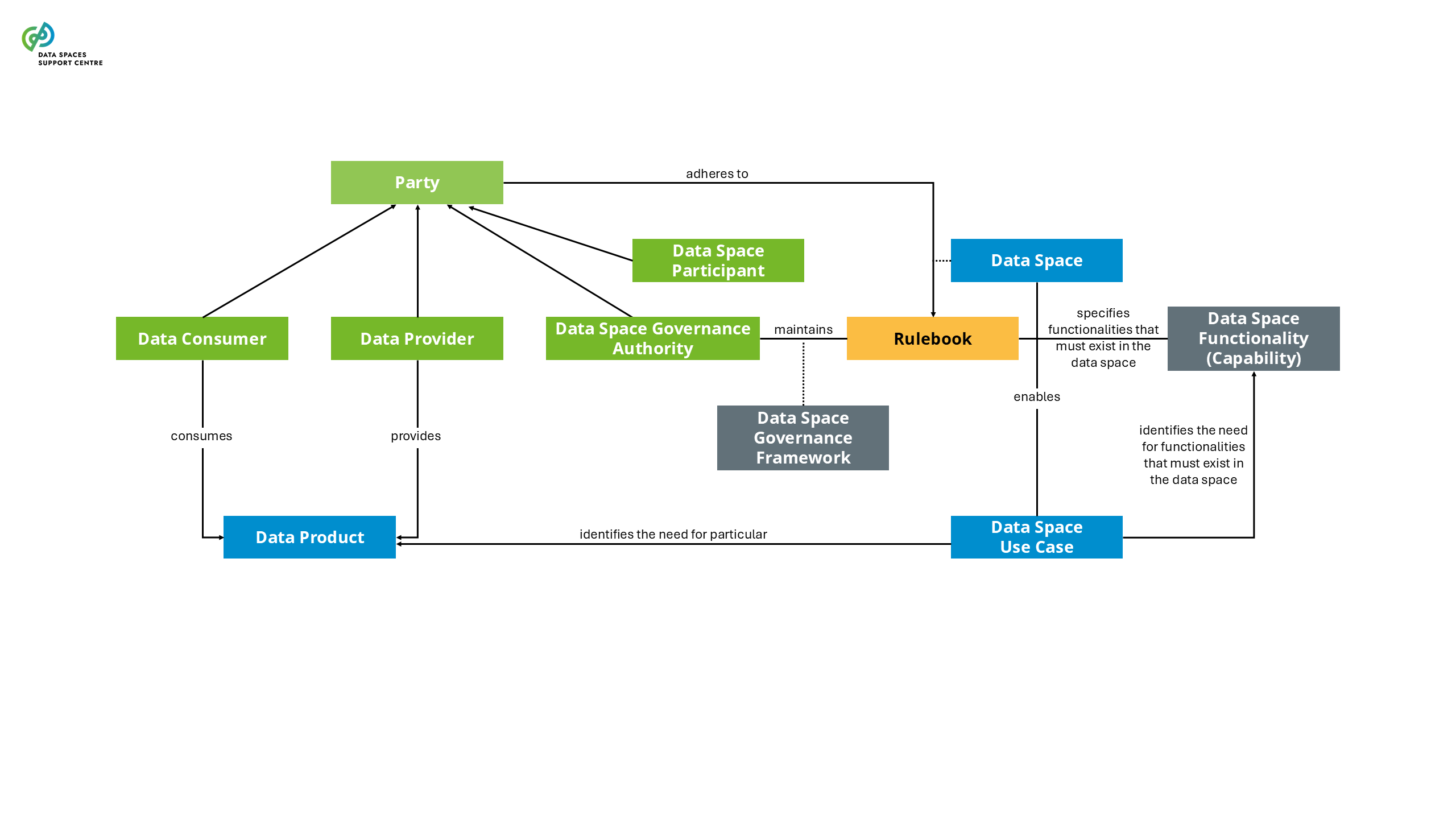
| Data Consumer
Source (vsn) : 5 Data Products and Transactions (bv30)
|
A synonym of data product consumer |
| Data Consumer
Source (vsn) : Publication and Discovery (bv30)
|
A consumer of data or service. |
| Data Element
Source (vsn) : Data Models (bv30)
|
the smallest units of data that carry a specific meaning within a dataset. Each data element has a name, a defined data type (such as text, number, or date), and often a description that explains what it represents. |
| Data Governance
Source (vsn) : Access & Usage Policies Enforcement (bv20)
|
framework of policies, processes, and standards that ensure effective management, quality, security, and proper use of data within an organization. |
| Data Governance Act
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
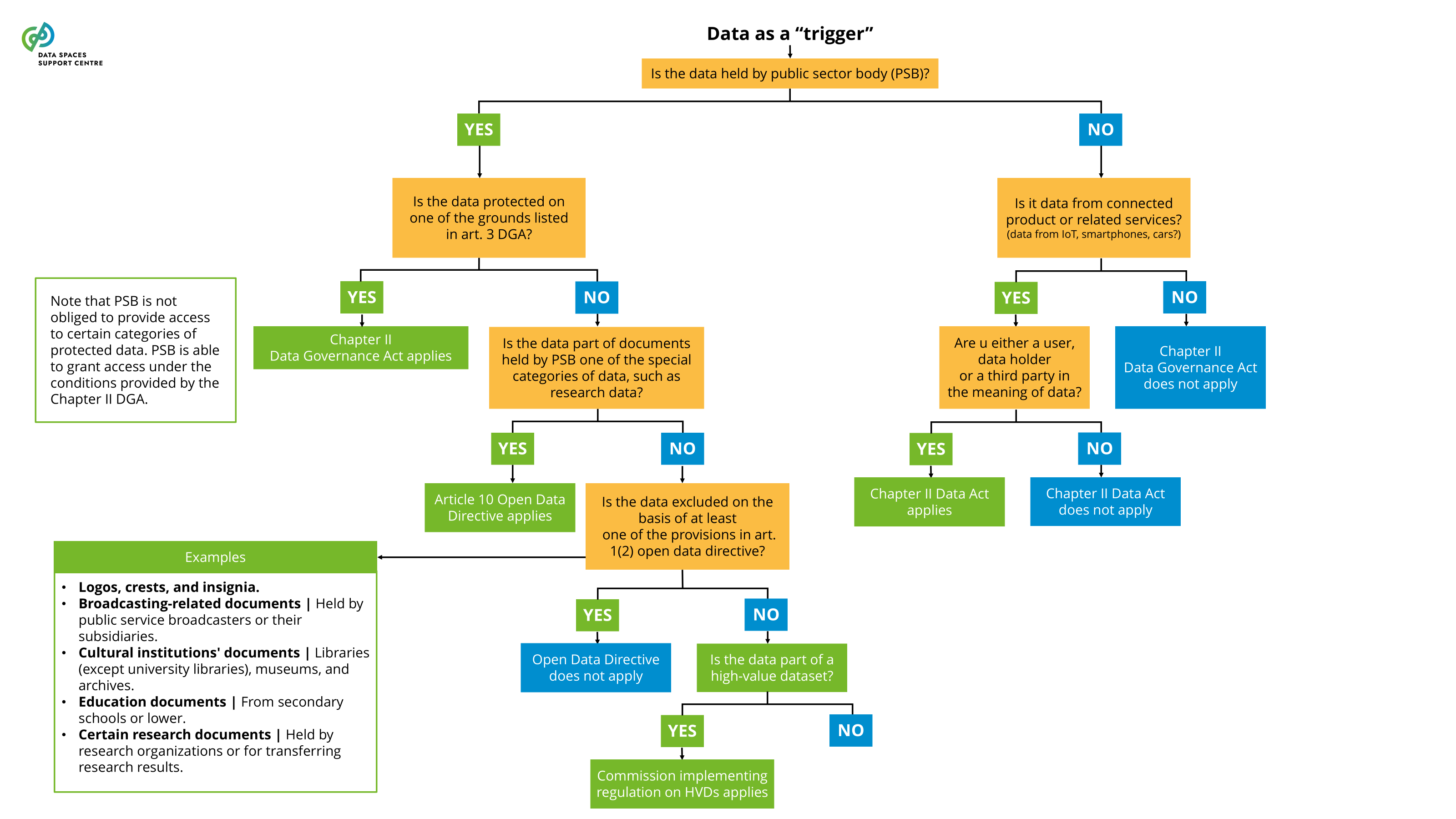
A European regulation that aims to create a framework to facilitate European data spaces and increase trust between actors in the data market. The DGA entered into force in June 2022 and applies from Sept 2023. The DGA defines the European Data Innovation Board (EDIB). |
| Data Holder
Source (vsn) : Regulatory Compliance (bv20)
|
a legal person, including public sector bodies and international organisations, or a natural person who is not a data subject with respect to the specific data in question, which, in accordance with applicable Union or national law, has the right to grant access to or to share certain personal data or non-personal data;( DGA Article 2(8) ) a natural or legal person that has the right or obligation, in accordance with this Regulation, applicable Union law or national legislation adopted in accordance with Union law, to use and make available data, including, where contractually agreed, product data or related service data which it has retrieved or generated during the provision of a related service;( DA Article 2(13))
Explanatory Text : In general context we use data holder within the meaning of DGA Art. 2(8) and in case the word data holder is used in the context of DA (IoT data), we identify it with DA at the end of the term. Please note that data rights holder has a specific and different meaning than data holder and is used especially in data transactions.
|
| Data Intermediation Service
Source (vsn) : Regulatory Compliance (bv20)
|
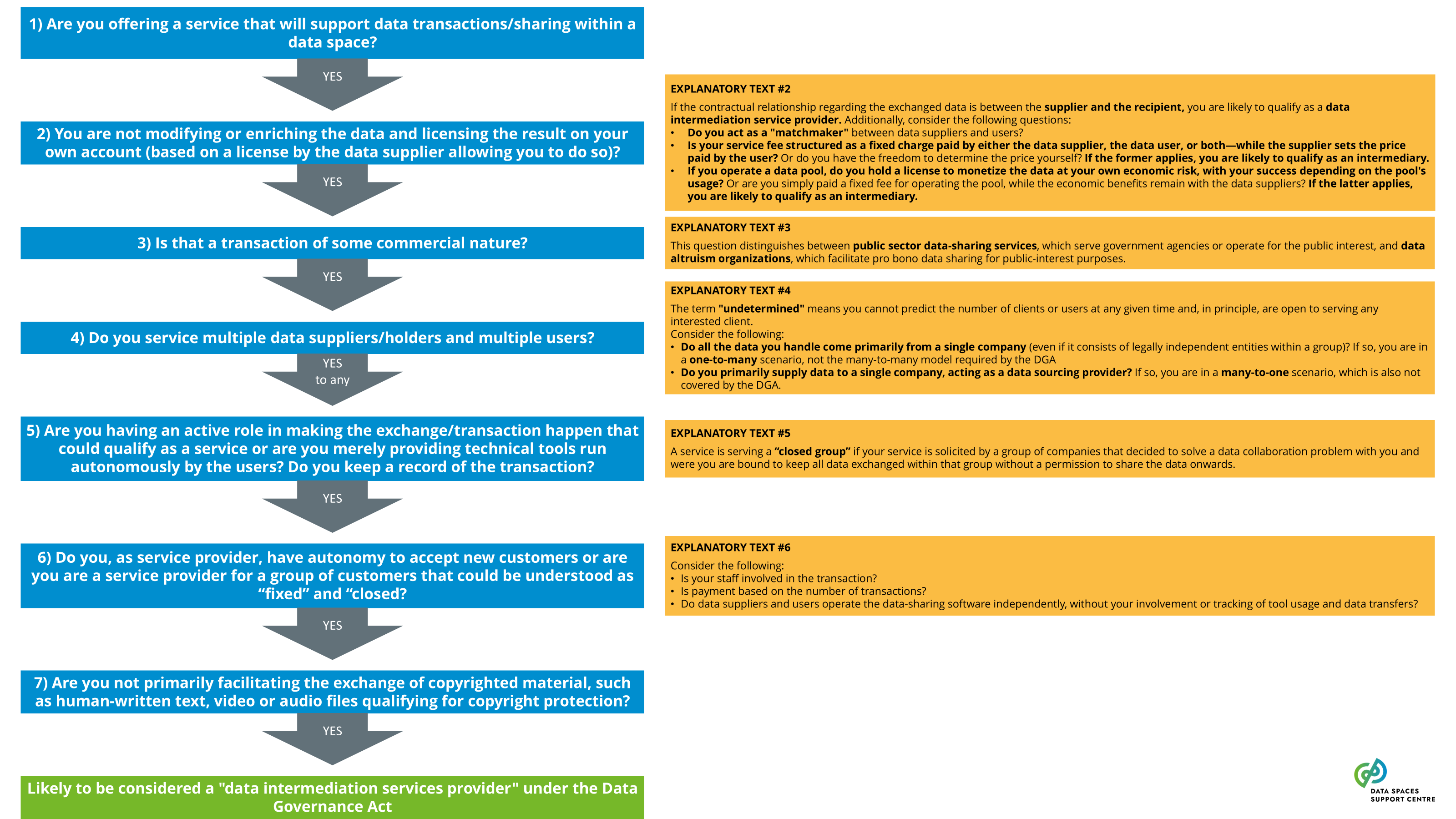
a service that is legally defined in the Data Governance Act and enforced by national agencies. An operator in a data space may qualify as a data intermediation service provider, depending on the scope of the services.DGA definition (simplified): ‘Data intermediation service’ means a service which aims to establish commercial relationships for the purposes of data sharing between an undetermined number of data subjects and data holders on the one hand and data users on the other through technical, legal or other means, including for the purpose of exercising the rights of data subjects in relation to personal data.( DGA Article 2 (11) )
Explanatory Text : Services that fall within this definition will be bound to comply with a range of obligations. The most important two are: (1) Service providers cannot use the data for other purposes than facilitating the exchange between the users of the service; (2) Services of intermediation (e.g. catalogue services, app stores) have to be separate from services providing applications. Both rules are meant to provide for a framework of truly neutral data intermediaries.
|
| Data Intermediation Service Providers (DISPs)
Source (vsn) : Types of Participants (Participant as a Trigger) (bv20)
|
The recent Data Governance Act (DGA) sets out specific requirements for providing data intermediation services. Certain service functions in data spaces are likely to qualify as data intermediation services (see: Data Intermediation Service Provider Flowchart ). A data space governance authority should also evaluate to what extent it organises any services that may qualify as data intermediation services under the DGA. If this is the case, it will need to ensure compliance with the provisions of the DGA.Data Intermediation Service under the Data Governance ActUnder the Data Governance Act, a “data intermediation service” (“DIS”) is defined as a service aiming to establish commercial relationships for the purposes of data sharing between an undetermined number of data subjects and data holders on the one hand and data users on the other.Data intermediation service providers intending to provide data intermediation services are required under the DGA to submit a notification to the competent national authority for data intermediation services. The provision of data intermediation services is subject to a range of conditions, including a limitation on the use by the provider of the data for which it provides data intermediation services.The European Commission hosts a register of data intermediation services recognised in the European Union: https://digital-strategy.ec.europa.eu/en/policies/data-intermediary-services Providers of data intermediation services and data space intermediaries/operatorsIntermediary services are covered more broadly in “ Data Space Intermediaries and Operators ”. The term “data space intermediary” refers to “a data space participant that provides one or more enabling services while not directly participating in the data transactions”. Enabling services refers to “a service that implements a data space functionality that enables data transactions for the transaction participants and/or operational processes for the governance authority.” (see the DSSC Glossary for more information)It is important to note that not all data space intermediaries would be subject to the provisions of the DGA by default. First of all, some of the potential enabling services they provide may not be aimed at establishing commercial relationships for the purposes of data sharing. It may also be the case that, in the circumstances at hand, the services may not result in commercial relationships between an undetermined number of data subjects and data holders on the one hand and data users on the other.Data intermediation services and personal dataThe services of data intermediation service providers may also relate to personal data. In such cases, it is important to appropriately consider the different roles and responsibilities under the DGA and the GDPR. For a transaction facilitated by a provider of data intermediation services, it is difficult to establish who is acting as the controller, whether there are multiple controllers acting as joint controllers, whether there is a processor and whether data users are data recipients. It may be important to clarify the respective responsibilities of particular data space participants by offering guidance to help ensure overall compliance with obligations under the DGA and the GDPR. |
| Data Model
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A structured representation of data elements and relationships used to facilitate semantic interoperability within and across domains, encompassing vocabularies, ontologies, application profiles and schema specifications for annotating and describing data sets and services.These abstraction levels may not need to be hierarchical; they can exist independently. |
| Data Model Provider
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
An entity responsible for creating, publishing, and maintaining data models within data spaces. This entity facilitates the management process of vocabulary creation, management, and updates. |
| Data Policy
Source (vsn) : 6 Data Policies and Contracts (bv30)
|
A set of rules, working instructions, preferences and other guidance to ensure that data is obtained, stored, retrieved, and manipulated consistently with the standards set by the governance framework and/or data rights holders.
Explanatory Text : Data policies govern aspects of data management within or between data spaces, such as access, usage, security, and hosting.
|
| Data Policy Enforcement
Source (vsn) : 6 Data Policies and Contracts (bv30)
|
A set of measures and mechanisms to monitor, control and ensure adherence to established data policies.
Explanatory Text : Policies can be enforced by technology or organisational manners.
|
| Data Policy Negotiation
Source (vsn) : 6 Data Policies and Contracts (bv30)
|
The process of reaching agreements on data policies between a data rights holder, a data provider and a data recipient. The negotiation can be fully machine-processable and immediate or involve human activities as part of the workflow. |
| Data Processing
Source (vsn) : Access & Usage Policies Enforcement (bv20)
|
Collection, manipulation, and transformation of raw data into meaningful information or results. |
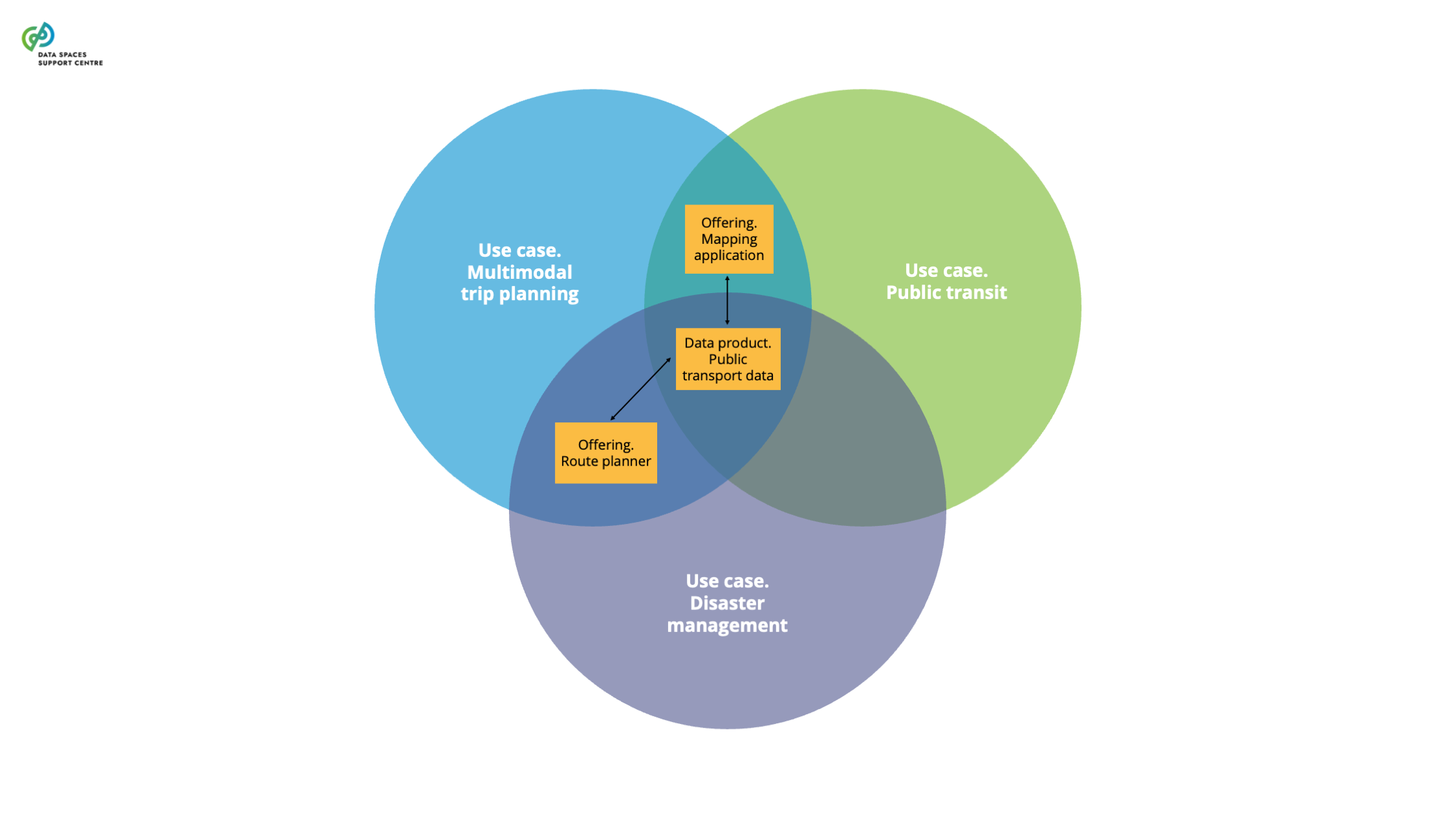
| Data Product
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- 5 Data Products and Transactions (bv30)
- Data Space Offering (bv20)
|
Data sharing units, packaging data and metadata, and any associated license terms.
Explanatory Texts :
- We borrow this definition from the CEN Workshop Agreement Trusted Data Transactions.
- The data product may include, for example, the data products' allowed purposes of use, quality and other requirements the data product fulfils, access and control rights, pricing and billing information, etc.
|
| Data Product Consumer
Sources (vsn) :
- 5 Data Products and Transactions (bv30)
- Data Space Offering (bv20)
|
A party that commits to a data product contract concerning one or more data products.
Explanatory Texts :
- A data product consumer is a data space participant.
- The data product consumer can be referred to as the data user. In principle, the data product consumer could be a different party than the eventual data user, but in many cases these parties are the same and the terms are used exchangeably.
|
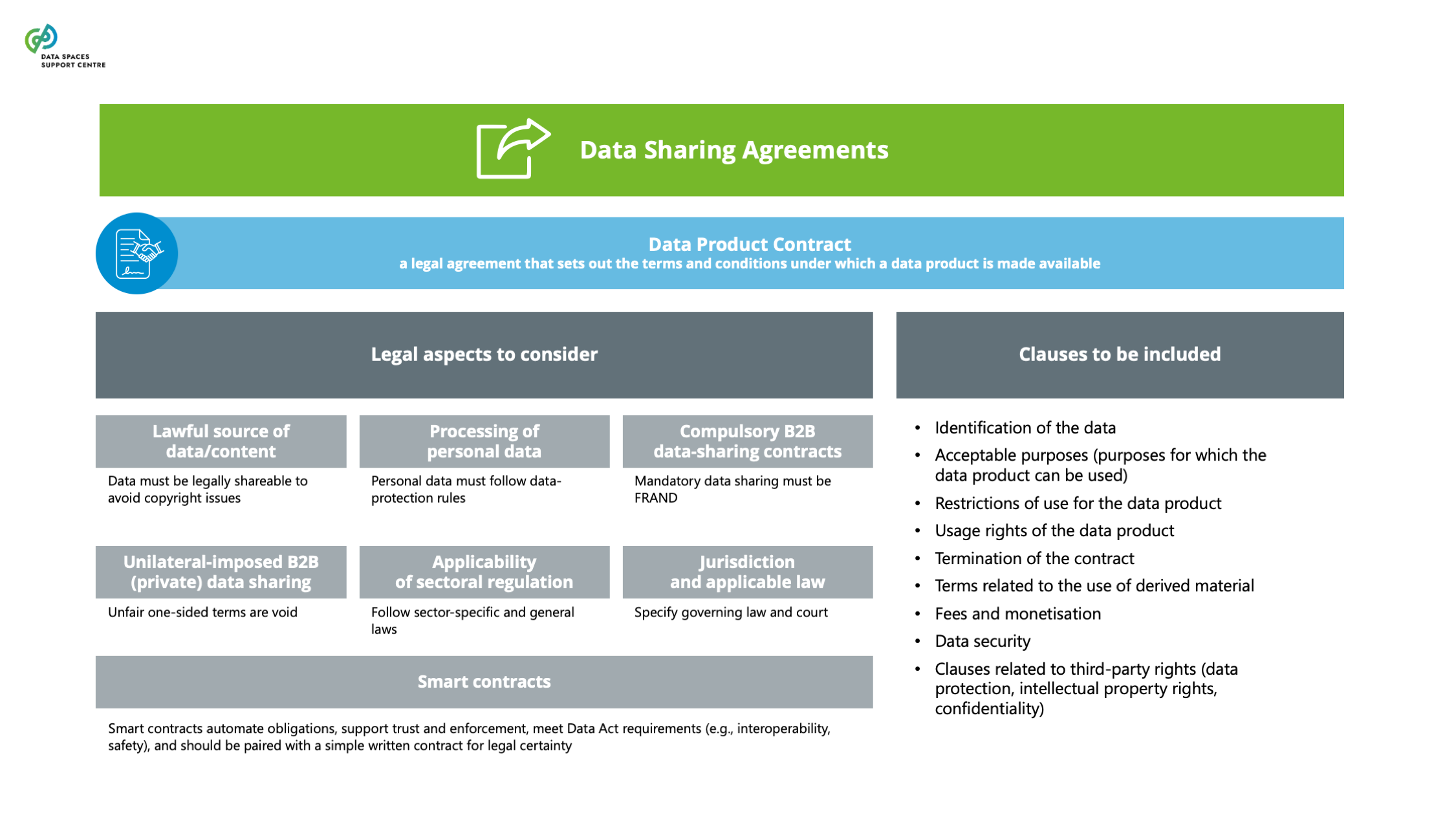
| Data Product Contract
Sources (vsn) :
- 5 Data Products and Transactions (bv30)
- Contractual Framework (bv30)
- Data Space Offering (bv20)
|
A legal contract that specifies a set of rights and duties for the respective parties that will perform the roles of the data product provider and data product consumer. |
| Data Product Owner
Sources (vsn) :
- 5 Data Products and Transactions (bv30)
- Data Space Offering (bv20)
|
A party that develops, manages and maintains a data product.
Explanatory Texts :
- The data product owner can be the same party as the data rights holder, or it can receive the right to process the data from the data rights holder (the right can be obtained through a permission, consent or license and may be ruled by a legal obligation or a contract).
- A data product owner is not necessarily a data space participant.
|
| Data Product Provider
Sources (vsn) :
- 5 Data Products and Transactions (bv30)
- Data Space Offering (bv20)
|
A party that acts on behalf of a data product owner in providing, managing and maintaining a data product in a data space.
Explanatory Texts :
- The data product provider can be referred to as the data provider. In general use that is fine, but in specific cases the data product provider might be a different party than the data rights holder and different than the data product owner.
- A data product provider is a data space participant.
- For reference, the definition from the CEN Workshop Agreement Trusted Data Transactions: a party that has the right or duty to make data available to data users through data products. Note: a data provider carries out several activities, ie.: - non-technical, on behalf of a data rights holder, including the description of the data products, data licence terms, the publishing of data products in a data product catalogue, the negotiation with the data users, and the conclusion of contracts, - technical, with the provision of the data products to the data users.
|
| Data Provider
Source (vsn) : 5 Data Products and Transactions (bv30)
|
A synonym of data product provider |
| Data Provider
Source (vsn) : Publication and Discovery (bv30)
|
A provider of data or service. |
| Data Recipient (Data Act)
Source (vsn) : Regulatory Compliance (bv20)
|
a natural or legal person, acting for purposes which are related to that person’s trade, business, craft or profession, other than the user of a connected product or related service, to whom the data holder makes data available, including a third party following a request by the user to the data holder or in accordance with a legal obligation under Union law or national legislation adopted in accordance with Union law;( DA Article 2(14) )
Explanatory Texts :
- Data recipient has a broader (not limited to IoT) meaning in the context of data transactions enabled by data space: ''A transaction participant to whom data is, or is to be technically supplied by a data provider in the context of a specific data transaction''.
- When we use data recipient in the meaning of DA (IoT data), we specify it with DA at the end of the word.
|
| Data Rights Holder
Sources (vsn) :
- 5 Data Products and Transactions (bv30)
- Access & Usage Policies Enforcement (bv20)
|
A party with legitimate interests to exercise rights under Union law affecting the use of data or imposing obligations on other parties in relation to the data.
Explanatory Texts :
- This party can be a data space participant, but not necessarily, when the party provides permission/consent for a data provider or data product provider to act on its behalf and participate in the actual data sharing.
- Previous definition (for reference): A party that has legal rights and/or obligations to use, grant access to or share certain personal or non-personal data. Data rights holders may transfer such rights to others.
- For reference, the definition from the CEN Workshop Agreement Trusted Data Transactions: a natural or legal person that has legal rights or obligations to use, grant access to or share certain data, or transfer such rights to others
|
| Data Schema
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A data model that defines the structure, data types, and constraints. Such a schema includes the technical details of the data structure for the data exchange, usually expressed in metamodel standards like JSON or XML Schema. |
| Data Service
Sources (vsn) :
- 4 Data Space Services (bv30)
- 5 Data Products and Transactions (bv20)
|
A collection of operations that provides access to one or more datasets or data processing functions. For example, data selection, extraction, data delivery. |
| Data Sharing
Source (vsn) : Regulatory Compliance (bv20)
|
the provision of data by a data subject or a data holder to a data user for the purpose of the joint or individual use of such data, based on voluntary agreements or Union or national law, directly or through an intermediary, for example under open or commercial licences subject to a fee or free of charge;( DGA Article 2(10) )
Explanatory Text : In the context of data spaces, data sharing refers to a full spectrum of practices related to sharing any kind of data, including all relevant technical, financial, legal, and organisational requirements.
|
| Data Sovereignty
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
The ability of individuals, organisations, and governments to have control over their data and exercise their rights on the data, including its collection, storage, sharing, and use by others.
Explanatory Text : Data sovereignty is a central concept in the European data strategy and recent European laws and regulations are expanding upon these rights and controls. EU law applies to data collected in the EU and/or about data subjects in the EU.
|
| Data Space
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
- Participation Management (bv30)
|
Interoperable framework, based on common governance principles, standards, practices and enabling services, that enables trusted data transactions between participants.
Explanatory Texts :
- Note for users of V0.5 and V1.0 of this blueprint: we have adopted this new definition from CEN Workshop Agreement Trusted Data Transactions, in an attempt to converge with ongoing standardisation efforts. Please note that further evolution might occur in future versions. For reference, the previous definition was: “Distributed system defined by a governance framework that enables secure and trustworthy data transactions between participants while supporting trust and data sovereignty. A data space is implemented by one or more infrastructures and enables one or more use cases.”
- Note: some parties write dataspace in a single word. We prefer data space in two words and consider that both terms mean exactly the same.
|
| Data Space Agreement
Source (vsn) : Contractual Framework (bv30)
|
A contract that states the rights and duties (obligations) of parties that have committed to (signed) it in the context of a particular data space. These rights and duties pertain to the data space and/or other such parties. |
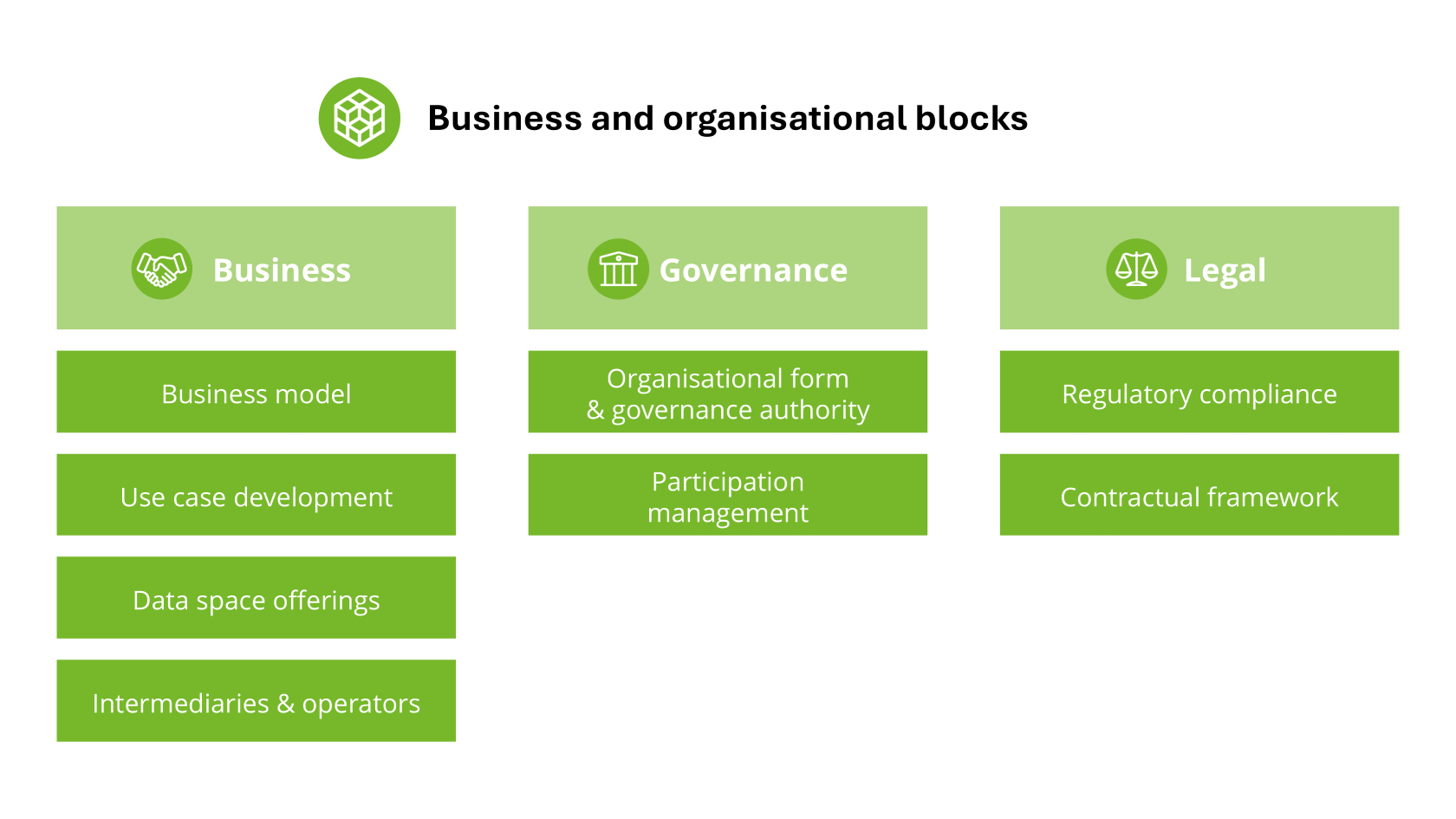
| Data Space Building Block
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
A description of related functionalities and/or capabilities that can be realised and combined with other building blocks to achieve the overall functionality of a data space.
Explanatory Texts :
- In the data space blueprint the building blocks are divided into organisational and business building blocks and technical building blocks.
- In many cases, the functionalities are implemented by Services
|
| Data Space Component
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
A specification for a software or other artefact that realises one service or a set of services that fulfil functionalities described by one or more building blocks.
Explanatory Text : For technical components, that would typically be software, but for business components, this could consist of processes, templates or other artefacts.
|
| Data Space Component Architecture
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
An overview of all the data space components and their interactions, providing a high-level structure of how these components are organised and interact within data spaces. |
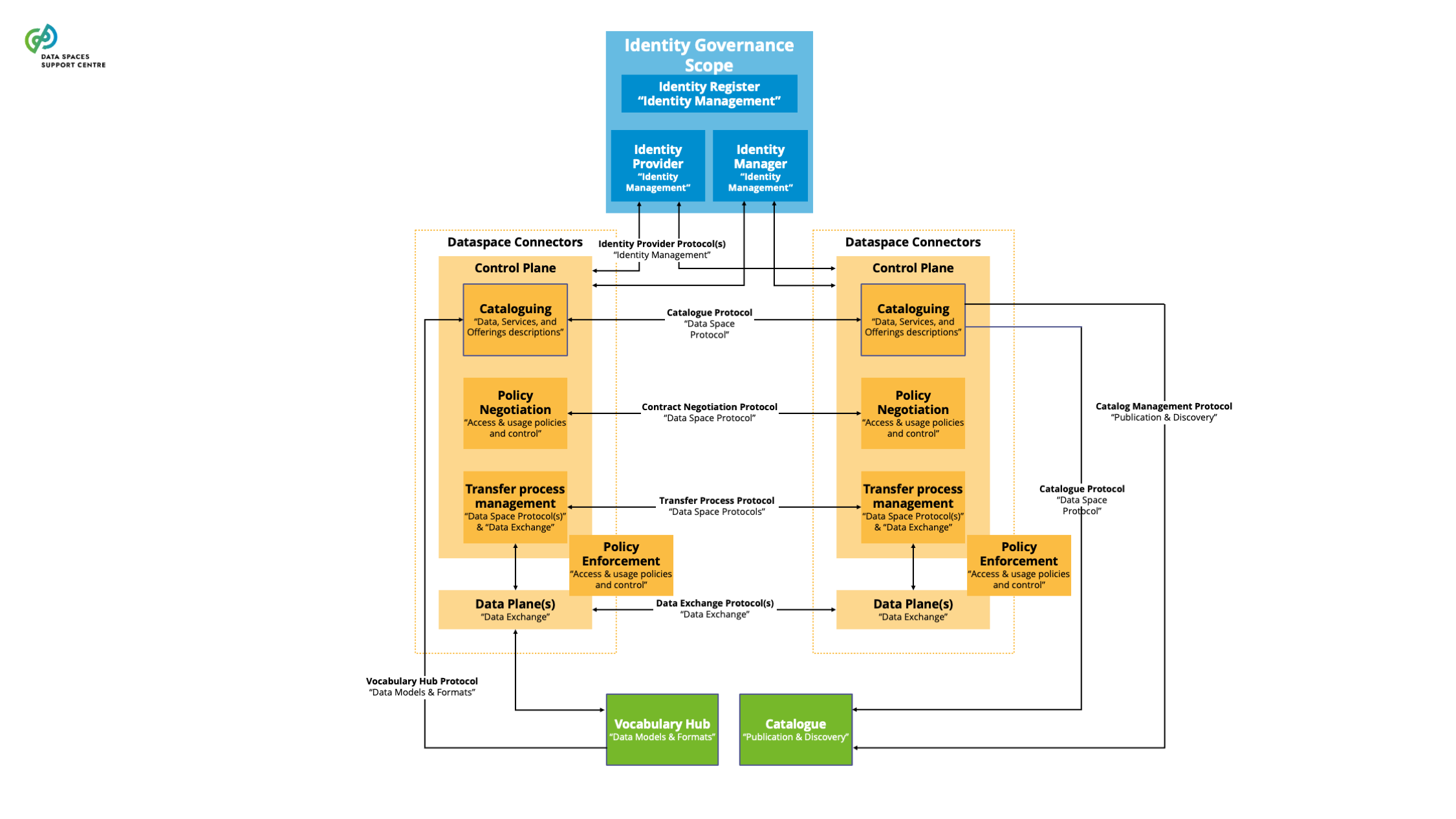
| Data Space Connector
Source (vsn) : 4 Data Space Services (bv20)
|
A technical component that is run by (or on behalf of) a participant and that provides participant agent services, with similar components run by (or on behalf of) other participants.
Explanatory Text : A connector can provide more functionality than is strictly related to connectivity. The connector can offer technical modules that implement data interoperability functions, authentication interfacing with trust services and authorisation, data product self-description, contract negotiation, etc. We use “participant agent services” as the broader term to define these services.
|
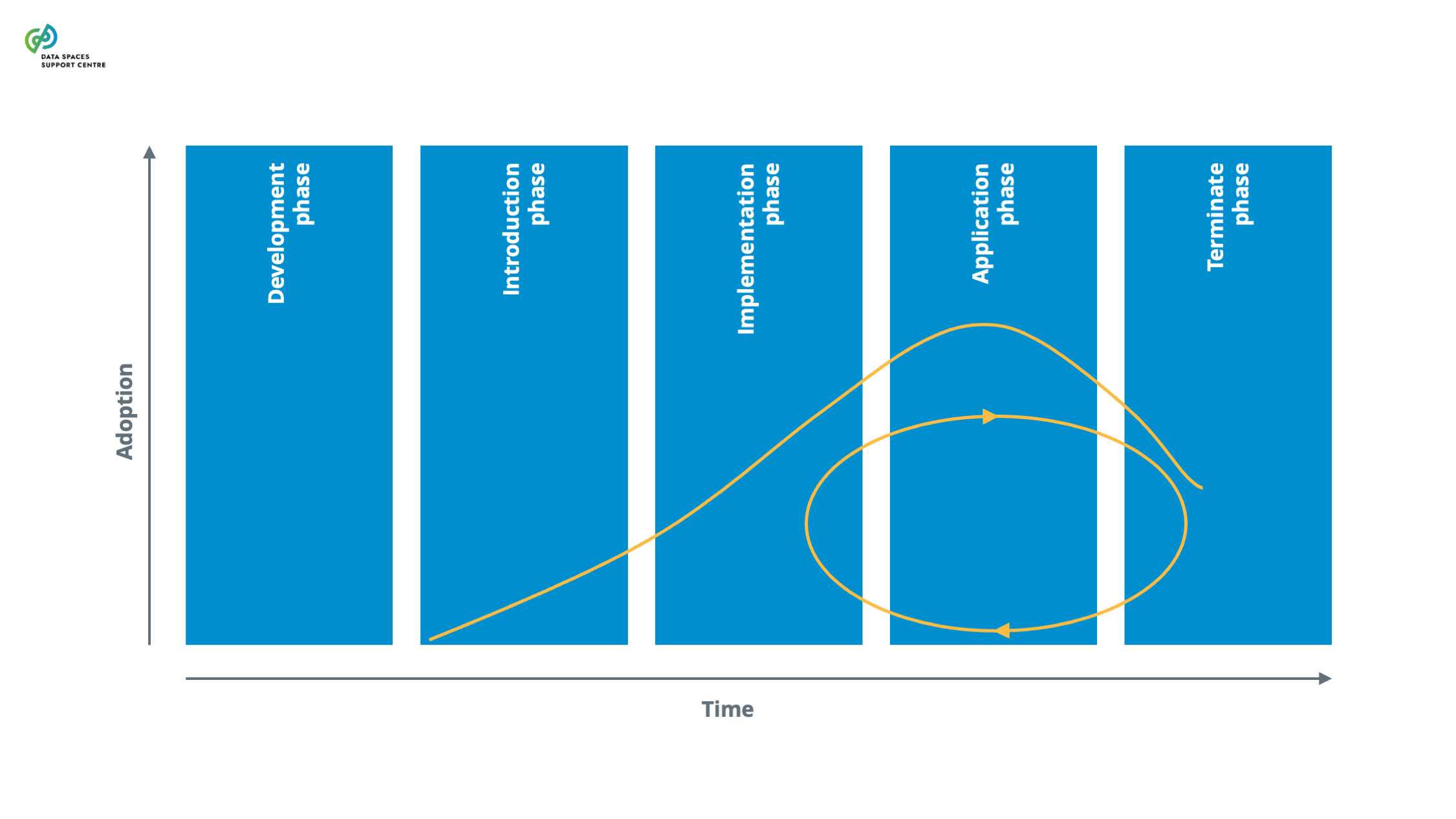
| Data Space Development Processes
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A set of essential processes the stakeholders of a data space initiative conduct to establish and continuously develop a data space throughout its development cycle. |
| Data Space Functionality
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A specified set of tasks that are critical for operating a data space and that can be associated with one or more data space roles.
Explanatory Text : The data space governance framework specifies the data space functionalities and associated roles. Each functionality and associated role consist of rights and duties for performing tasks related to that functionality.
|
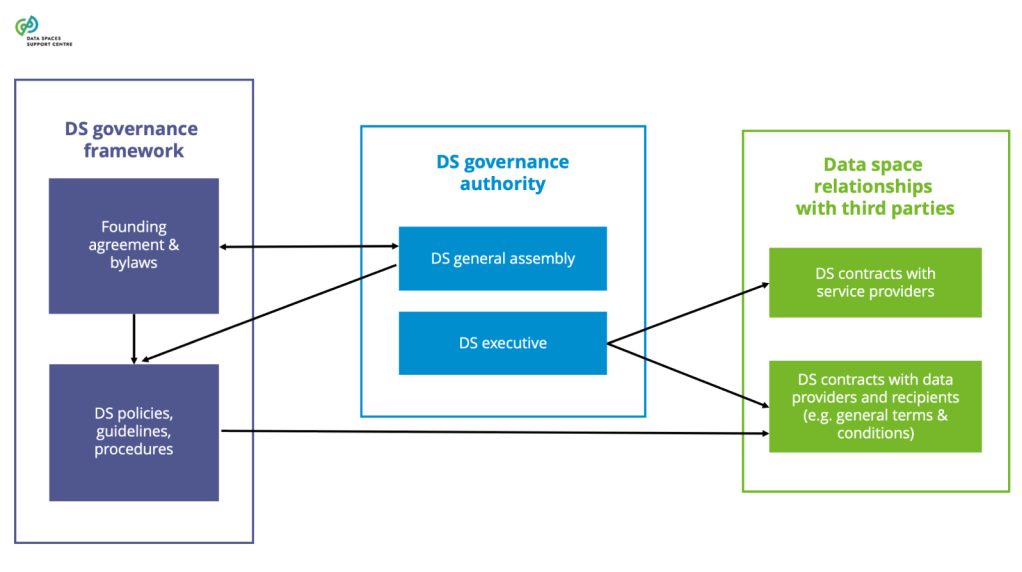
| Data Space Governance Authority
Source (vsn) : 1 Key Concept Definitions (bv30)
|
The body of a particular data space, consisting of participants that is committed to the governance framework for the data space, and is responsible for developing, maintaining, operating and enforcing the governance framework.
Explanatory Texts :
- A ‘body’ is a group of parties that govern, manage, or act on behalf of a specific purpose, entity, or area of law. This term, which has legal origins, can encompass entities like legislative bodies, governing bodies, or corporate bodies.
- The data space governance authority does not replace the role of public regulation and enforcement authorities.
- Establishing the initial data space governance framework is outside the governance authority's scope and needs to be defined by a group of data space initiating parties.
- After establishment, the governance authority performs the governing function (developing and maintaining the governance framework) and the executive function (operating and enforcing the governance framework).
- Depending on the legal form and the size of the data space, the governance and executive functions of a data space governance authority may or may not be performed by the same party.
|
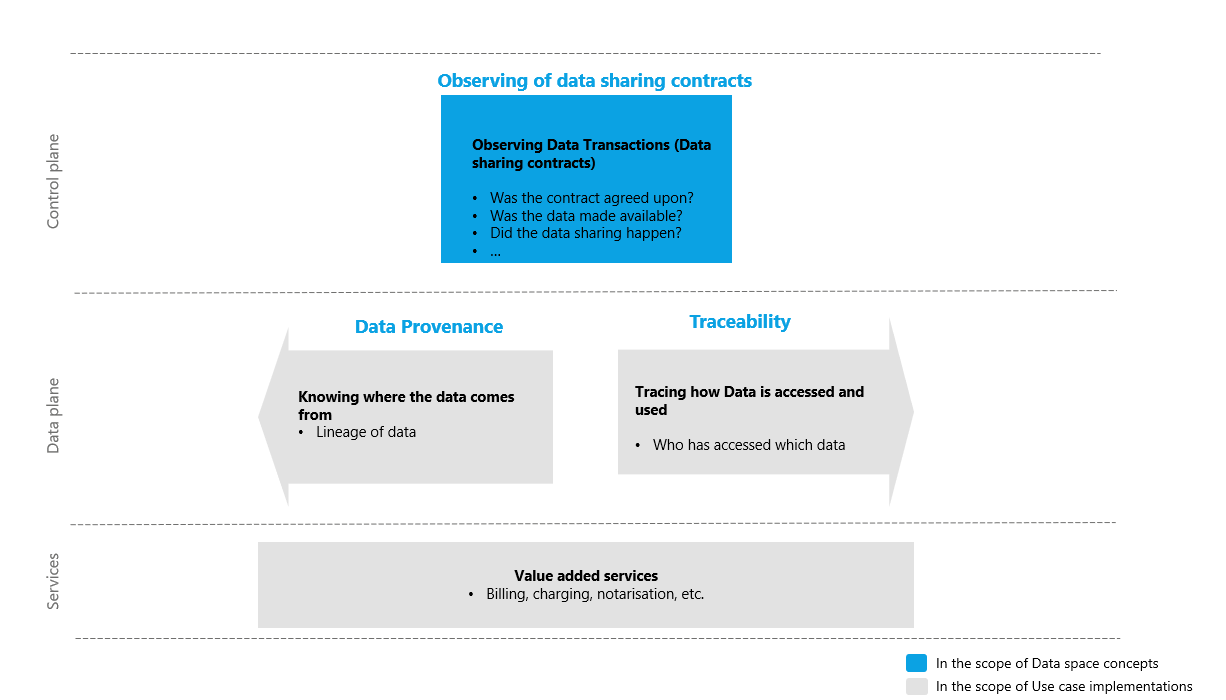
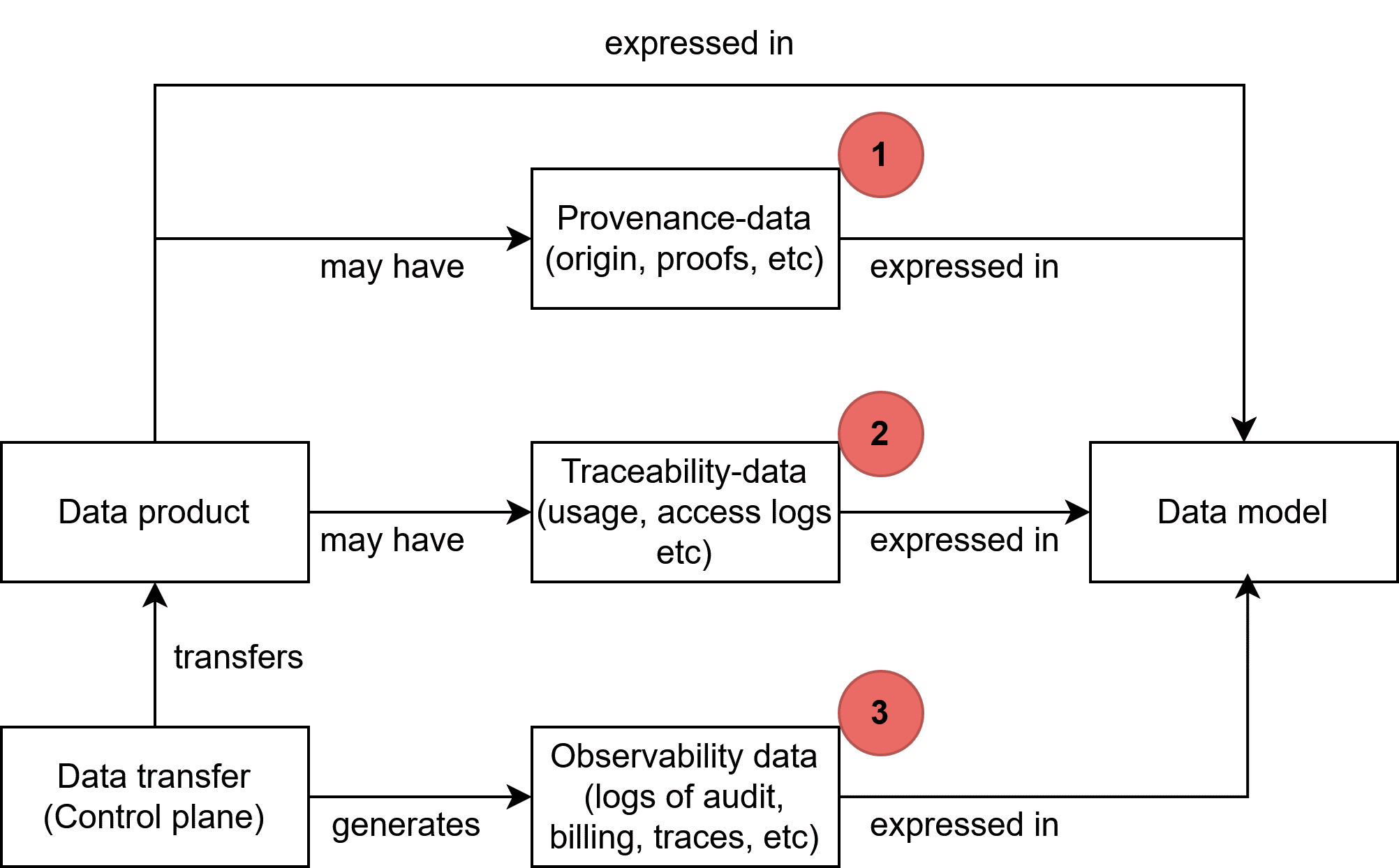
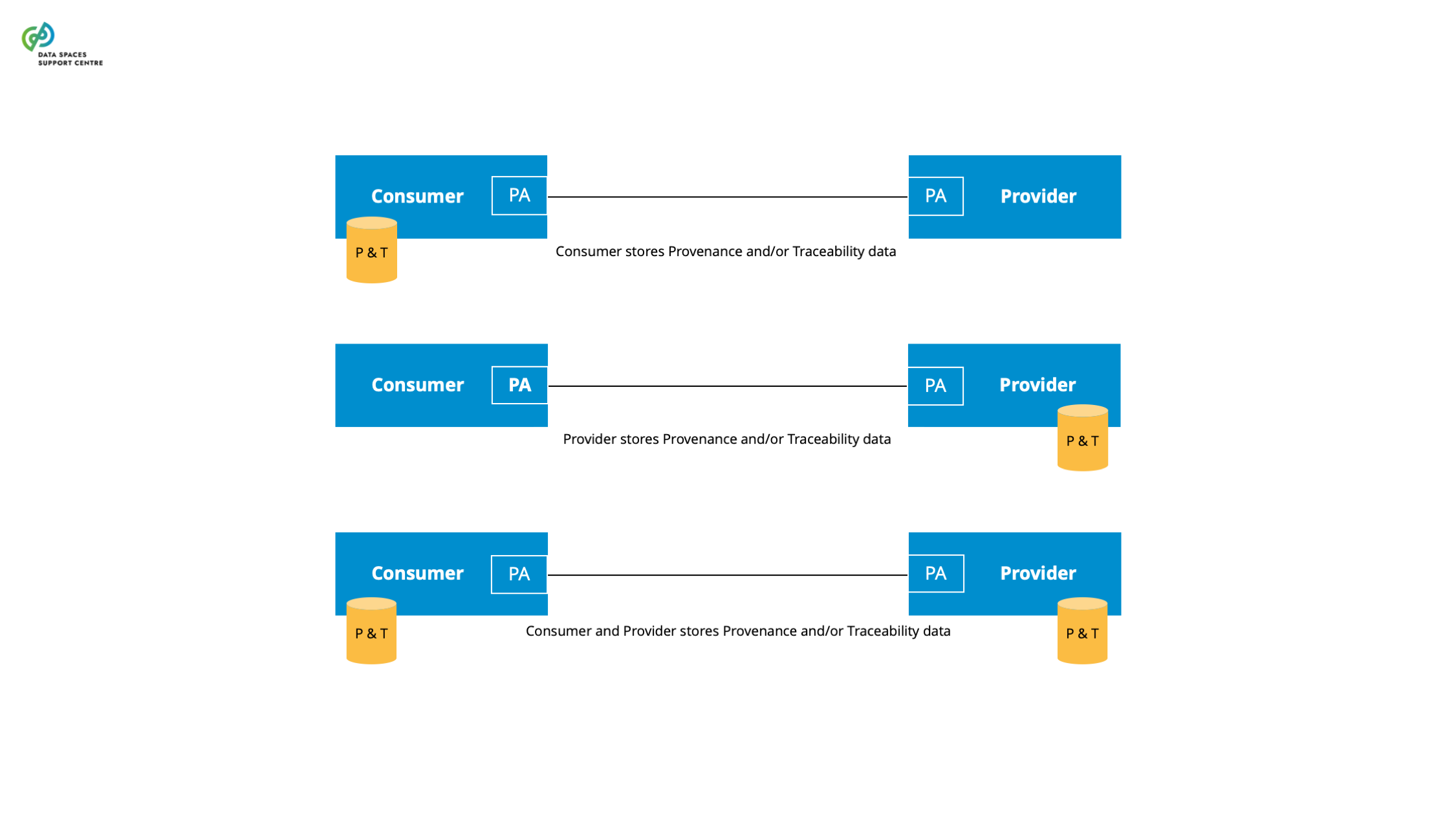
| Data Space Governance Authority
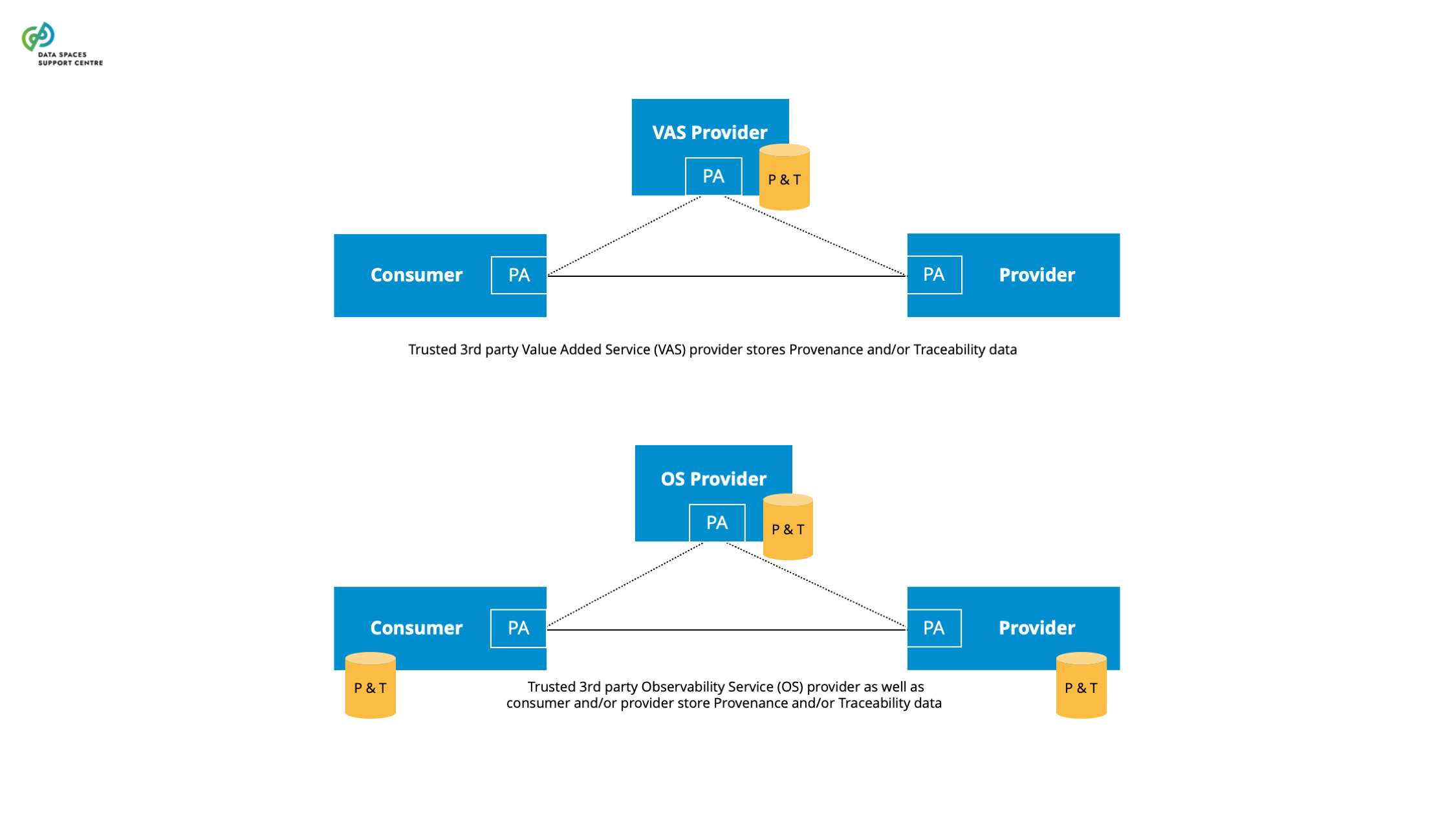
Source (vsn) : Provenance, Traceability & Observability (bv30)
|
A governance authority refers to bodies of a data space that are composed of and by data space participants responsible for developing and maintaining as well as operating and enforcing the internal rules. |
| Data Space Governance Authority
Sources (vsn) :
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
The body of a particular data space, consisting of participants that are committed to the governance framework for the data space, and is responsible for developing, maintaining, operating and enforcing the governance framework. |
| Data Space Governance Authority (DSGA)
Source (vsn) : Participation Management (bv30)
|
The body of a particular data space, consisting of participants that is committed to the governance framework for the data space, and is responsible for developing, maintaining, operating and enforcing the governance framework. |
| Data Space Governance Framework
Source (vsn) : 1 Key Concept Definitions (bv30)
|
The structured set of principles, processes, standards, protocols, rules and practices that guide and regulate the governance, management and operations within a data space to ensure effective and responsible leadership, control, and oversight. It defines the functionalities the data space provides and the associated data space roles, including the data space governance authority and participants.
Explanatory Texts :
- Functionalities include, e.g., the maintenance of the governance framework the functioning of the data space governance authority and the engagement of the participants.
- The responsibilities covered in the governance framework include assigning the governance authority and formalising the decision-making powers of participants.
- The data space governance framework specifies the procedures for enforcing the governance framework and conflict resolution.
- The operations may also include business and technology aspects.
|
| Data Space Infrastructure (deprecated Term)
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A technical, legal, procedural and organisational set of components and services that together enable data transactions to be performed in the context of one or more data spaces.
Explanatory Text : This term was used in the data space definition in previous versions of the Blueprint. It is replaced by the governance framework and enabling services, and may be deprecated from this glossary in a future version.
|
| Data Space Initiative
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A collaborative project of a consortium or network of committed partners to initiate, develop and maintain a data space. |
| Data Space Intermediary
Sources (vsn) :
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
|
A data space intermediary is a service provider who provides an enabling service or services in a data space. In common usage interchangeable with ‘operator'. |
| Data Space Interoperability
Source (vsn) : 7 Interoperability (bv30)
|
The ability of participants to seamlessly exchange and use data within a data space or between two or more data spaces.
Explanatory Texts :
- Interoperability generally refers to the ability of different systems to work in conjunction with each other and for devices, applications or products to connect and communicate in a coordinated way without effort from the users of the systems. On a high-level, there are four layers of interoperability: legal, organisational, semantic and technical (see the European Interoperability Framework [EIF]).
- Legal interoperability: Ensuring that organisations operating under different legal frameworks, policies and strategies are able to work together.
- Organisational interoperability: The alignment of processes, communications flows and policies that allow different organisations to use the exchanged data meaningfully in their processes to reach commonly agreed and mutually beneficial goals.
- Semantic interoperability: The ability of different systems to have a common understanding of the data being exchanged.
- Technical interoperability: The ability of different systems to communicate and exchange data.
- Also the ISO/IEC 19941:2017 standard [20] is relevant here.
- Note: As per Art. 2 r.40 of the Data Act: ‘interoperability’ means the ability of two or more data spaces or communication networks, systems, connected products, applications, data processing services or components to exchange and use data in order to perform their functions. We describe this wider term as cross-data space interoperability.
|
| Data Space Maturity Model
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
Set of indicators and a self-assessment tool allowing data space initiatives to understand their stage in the development cycle, their performance indicators and their technical, functional, operational, business and legal capabilities in absolute terms and in relation to peers. |
| Data Space Offering
Source (vsn) : Data Space Offering (bv20)
|
The set of offerings provided through the data space that aim to bring value to participants. |
| Data Space Operational Processes
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A set of essential processes a potential or actual data space participant goes through when engaging with a functioning data space that is in the operational stage or scaling stage. The operational processes include attracting and onboarding participants, publishing and matching use cases, data products and data requests and eventually data transactions. |
| Data Space Participant
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
- Participation Management (bv30)
|
A party committed to the governance framework of a particular data space and having a set of rights and obligations stemming from this framework.
Explanatory Text : Depending on the scope of the said rights and obligations, participants may perform in (multiple) different roles, such as: data space members, data space users, data space service providers and others as described in this glossary.
|
| Data Space Pilot
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A planned and resourced implementation of one or more use cases within the context of a data space initiative. A data space pilot aims to validate the approach for a full data space deployment and showcase the benefits of participating in the data space. |
| Data Space Role
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- Participation Management (bv30)
|
A distinct and logically consistent set of rights and duties (responsibilities) within a data space, that are required to perform specific tasks related to a data space functionality, and that are designed to be performed by one or more participants.
Explanatory Texts :
- The governance framework of a data space defines the data space roles.
- Parties can perform (be assigned, or simply ‘be’) multiple roles, such as data provider, transaction participant, data space intermediary, etc.. In some cases, a prerequisite for performing a particular role is that the party can already perform one or more other roles. For example, the data provider must also be a data space participant.
|
| Data Space Rulebook
Source (vsn) : 1 Key Concept Definitions (bv30)
|
The documentation of the data space governance framework for operational use.
Explanatory Text : The rulebook can be expressed in human-readable and machine-readable formats.
|
| Data Space Service Offering Credential
Source (vsn) : Identity & Attestation Management (bv30)
|
A service description that follows the schemas defined by the Data Space Governance Authority and whose claims are validated by the Data Space Compliance Service. |
| Data Space Services
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- 4 Data Space Services (bv30)
|
Functionalities for implementing data space capabilities, offered to participants of data spaces.
Explanatory Texts :
- We distinguish three classes of technical services which are further defined in section 4 of this glossary: Participant Agent Services, Facilitating Services, Value-Creation Services. Technical (software) components are needed to implement these services.
- Also on the business and organisational side, services may exist to support participants and orchestrators of data spaces, further defined in section 4 of this glossary and discussed in the Business and Organisational building blocks introduction.
- Please note that a Data Service is a specific type of service related to the data space offering, providing access to one or more datasets or data processing functions.
|
| Data Space Support Organisation
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
An organisation, consortium, or collaboration network that specifies architectures and frameworks to support data space initiatives. Examples include Gaia-X, IDSA, FIWARE, iSHARE, MyData, BDVA, and more. |
| Data Space Use Case
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A specific setting in which two or more participants use a data space to create value (business, societal or environmental) from data sharing.
Explanatory Texts :
- By definition, a data space use case is operational. When referring to a planned or envisioned setting that is not yet operational we can use the term use case scenario.
- Use case scenario is a potential use case envisaged to solve societal, environmental or business challenges and create value. The same use case scenario, or variations of it, can be implemented as a use case multiple times in one or more data spaces.
|
| Data Space Value
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
The cumulative value generated from all the data transactions and use cases within a data space as data space participants collaboratively use it.
Explanatory Text : The definition of “data space value” is agnostic to value sharing and value capture. It just states where the value is created (in the use cases). The use case orchestrator should establish a value-sharing mechanism within the use case to make all participants happy. Furthermore, to avoid the free rider problem, the data space governance authority may also want to establish a value capture mechanism (for example, a data space usage fee) to get its part from the value created in the use cases.
|
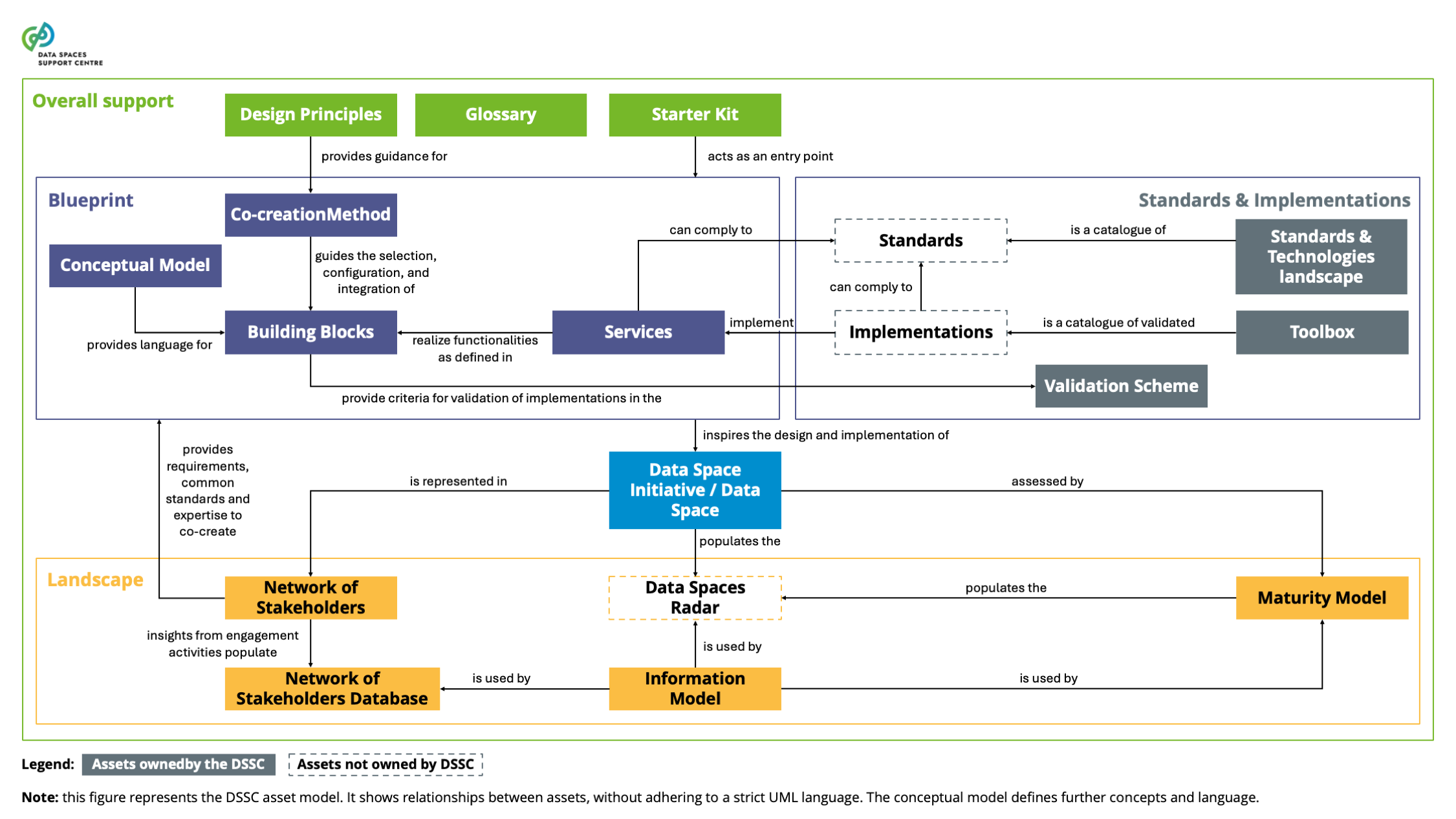
| Data Spaces Blueprint
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
A consistent, coherent and comprehensive set of guidelines to support the implementation, deployment and maintenance of data spaces.
Explanatory Text : The blueprint contains the conceptual model of data space, data space building blocks, and recommended selection of standards, specifications and reference implementations identified in the data spaces technology landscape.
|
| Data Spaces Information Model
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A classification scheme used to describe, analyse and organise a data space initiative according to a defined set of questions. |
| Data Spaces Radar
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A publicly accessible tool to provide an overview of the data space initiatives, their sectors, locations and approximate development stages. |
| Data Spaces Starter Kit
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A document that helps organisations and individuals in the network of stakeholders to understand the requirements for creating a data space. |
| Data Spaces Support Centre
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
The virtual organisation and EU-funded project which supports the deployment of common European data spaces and promotes the reuse of data across sectors. |
| Data Spaces Technology Landscape
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A repository of standards (de facto and de jure), specifications and open-source reference implementations available for deploying data spaces. The Data Space Support Centre curates the repository and publishes it with the blueprint. |
| Data Storage
Source (vsn) : Access & Usage Policies Enforcement (bv20)
|
Process of saving digital data in a physical or virtual location for future retrieval and use. |
| Data Subject
Source (vsn) : Regulatory Compliance (bv20)
|
an identified or identifiable natural person that personal data relates to.( GDPR Article 4(1) )
Explanatory Text : Data subject is implicitly defined in the definition of ‘personal data’. In the context of data spaces we use the broader term data rights holder, to refer to the party that has (legal) rights and/or obligations to use, grant access to or share certain personal or non-personal data. For personal data, this would equal the data subject.
|
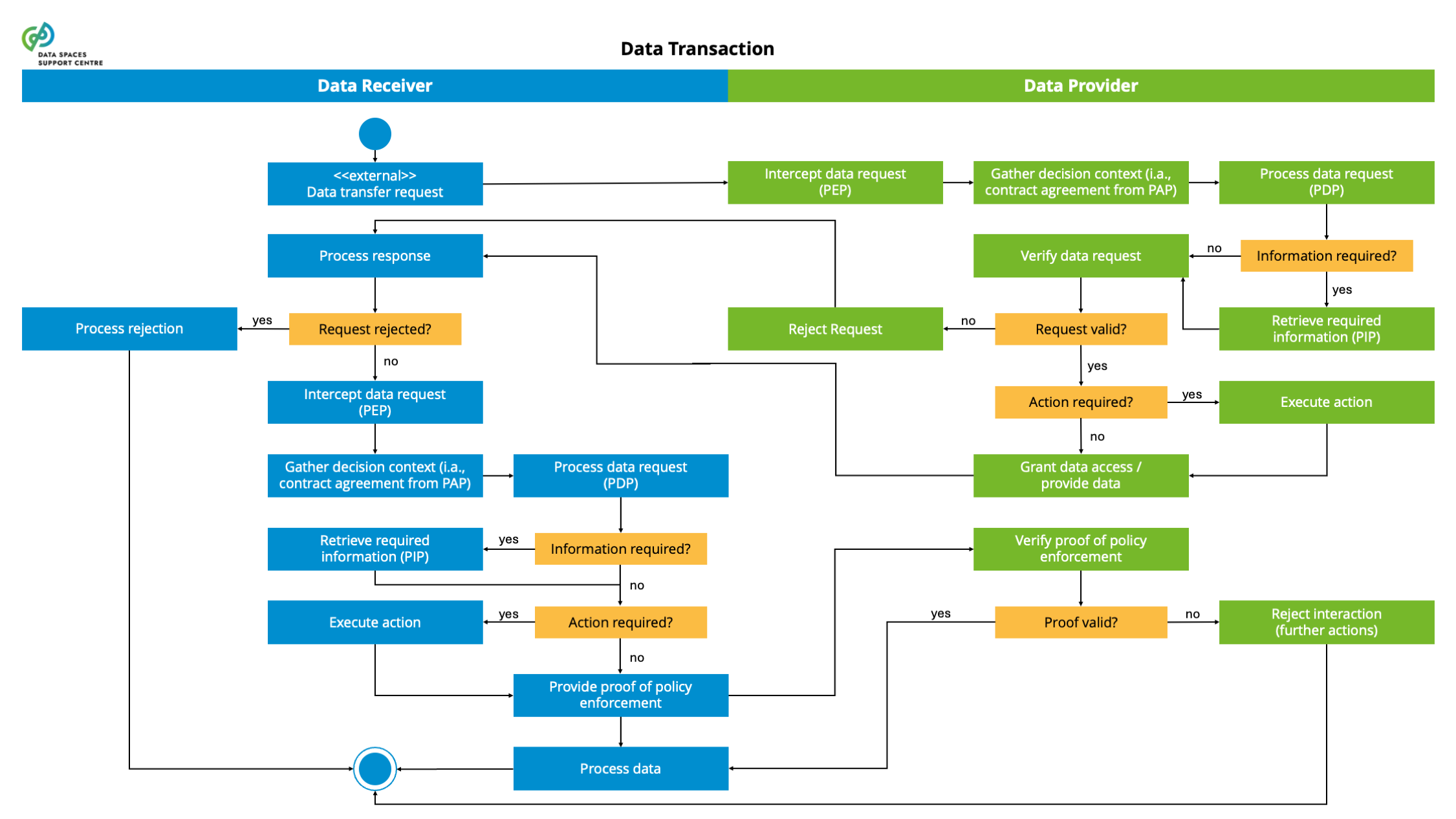
| Data Transaction
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- Participation Management (bv30)
|
A structured interaction between data space participants for the purpose of providing and obtaining/using a data product. An end-to-end data transaction consists of various phases, such as contract negotiation, execution, usage, etc.
Explanatory Texts :
- In future work we may align further with the definition from CEN Workshop Agreement Trusted Data Transactions: result of an agreement between a data provider and a data user with the purpose of exchanging, accessing and using data, in return for monetary or non-monetary compensation.
- A data transaction implies data transfer among involved participants and its usage on a lawful and contractual basis. It relates to the technical, financial, legal and organisational arrangements necessary to make a data set from Participant A available to Participant B. The physical data transfer may or may not happen during the data transaction.
- Prerequisites:
- the specification of data products and the creation and publication of data product offerings so parties can search for offerings, compare them and engage in data transactions to obtain the offered data product.
- Key elements related to data transactions are:
- negotiation (at the business level) of a contract between the provider and user of a data product, which includes, e.g., pricing, the use of appropriate intermediary services, etc.
- negotiation (at the operational level) of an agreement between the provider and the user of a data product, which includes, e.g., technical policies and configurations, such as sending
- ensuring that parties that provide, receive, use, or otherwise act with the data have the rights/duties they need to comply with applicable policies and regulations (e.g. from the EU)
- accessing and/or transferring the data (product) between provider, user, and transferring this data and/or meta-data to (contractually designated) other participants, such as observers, clearing house services, etc.
- Data access and data usage by the data consumer.
- All activities listed above do not need to be conducted in every transaction and that parts of the activities may be visited in loops or conditional flows.
|
| Data Transaction
Source (vsn) : Participation Management (bv20)
|
In the operational and scaling stage of a data space, the number of participants and use cases grows organically. The Data Space Governance Framework defines roles, responsibilities, and policies for data management, while the task of the Data Space Governance Authority is to enable seamless interaction among the participants. While use cases are executed and data products and data requests are published by the participants, the Data Space Governance Authority must carefully consider imbalances between supply and demand and consequently establish means to attract new participants to the data space to tackle the imbalances.As the data space grows, the Data Space Governance Authority needs to regularly screen the governance framework and eventually adapt it to address emerging needs and challenges. These adaptations may arise from various factors, such as regulatory changes that impose new requirements on participants, or the strategic goal of expanding the data space to include new industries, companies, or countries with distinct regulations and standards. To successfully accommodate such expansions, the governance framework must remain flexible and inclusive, enabling the integration of diverse stakeholders while maintaining robust compliance, security, and interoperability. Potential adaptations must remain in line with the data space’s central mission/vision. |
| Data Usage Policy
Source (vsn) : 6 Data Policies and Contracts (bv30)
|
A specific data policy defined by the data rights holder for the usage of their data shared in a data space.
Explanatory Text : Data usage policy regulates the permissible actions and behaviours related to the utilisation of the accessed data, which means keeping control of data even after the items have left the trust boundaries of the data provider.
|
| Data User
Source (vsn) : Regulatory Compliance (bv20)
|
a natural or legal person who has lawful access to certain personal or non-personal data and has the right, including under Regulation (EU) 2016/679 in the case of personal data, to use that data for commercial or noncommercial purposes;( DGA Article 2 (9)) |
| Data User
Source (vsn) : 5 Data Products and Transactions (bv30)
|
a natural or legal person who has lawful access to certain personal or non-personal data and has the right, including under Regulation (EU) 2016/679 in the case of personal data, to use that data for commercial or noncommercial purposes; ( DGA Article 2 (9))
Explanatory Texts :
- In many cases the data user is the same party as the data consumer or data product consumer, but exceptions may exist where these roles are separate.
- For reference, the definition from the CEN Workshop Agreement Trusted Data Transactions which considers the term to be synonymous with data consumer: person or organization authorized to exploit data (ISO 5127:2017) Note 1: Data are in the form of data products. Note 2: Data consumer is considered as a synonym of data user.
|
| Dataset Description
Sources (vsn) :
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
|
A description of a dataset includes various attributes, such as spatial, temporal, and spatial resolution. The description encompasses attributes related to distribution of datasets such as data format, packaging format, compression format, frequency of updates, download URL, and more. These attributes provide essential metadata that enables data recipients to understand the nature and usability of the datasets. |
| Dataspace Protocol
Source (vsn) : Provenance, Traceability & Observability (bv30)
|
The Eclipse data space Protocol is a set of specifications that enable secure, interoperable data sharing between independent entities by defining standardized models, contracts, and processes for publishing, negotiating, and transferring data within data space s.The current specification can be found at: https://eclipse-dataspace-protocol-base.github.io/DataspaceProtocol |
| Declaration
Source (vsn) : Identity & Attestation Management (bv30)
|
first-party attestation (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
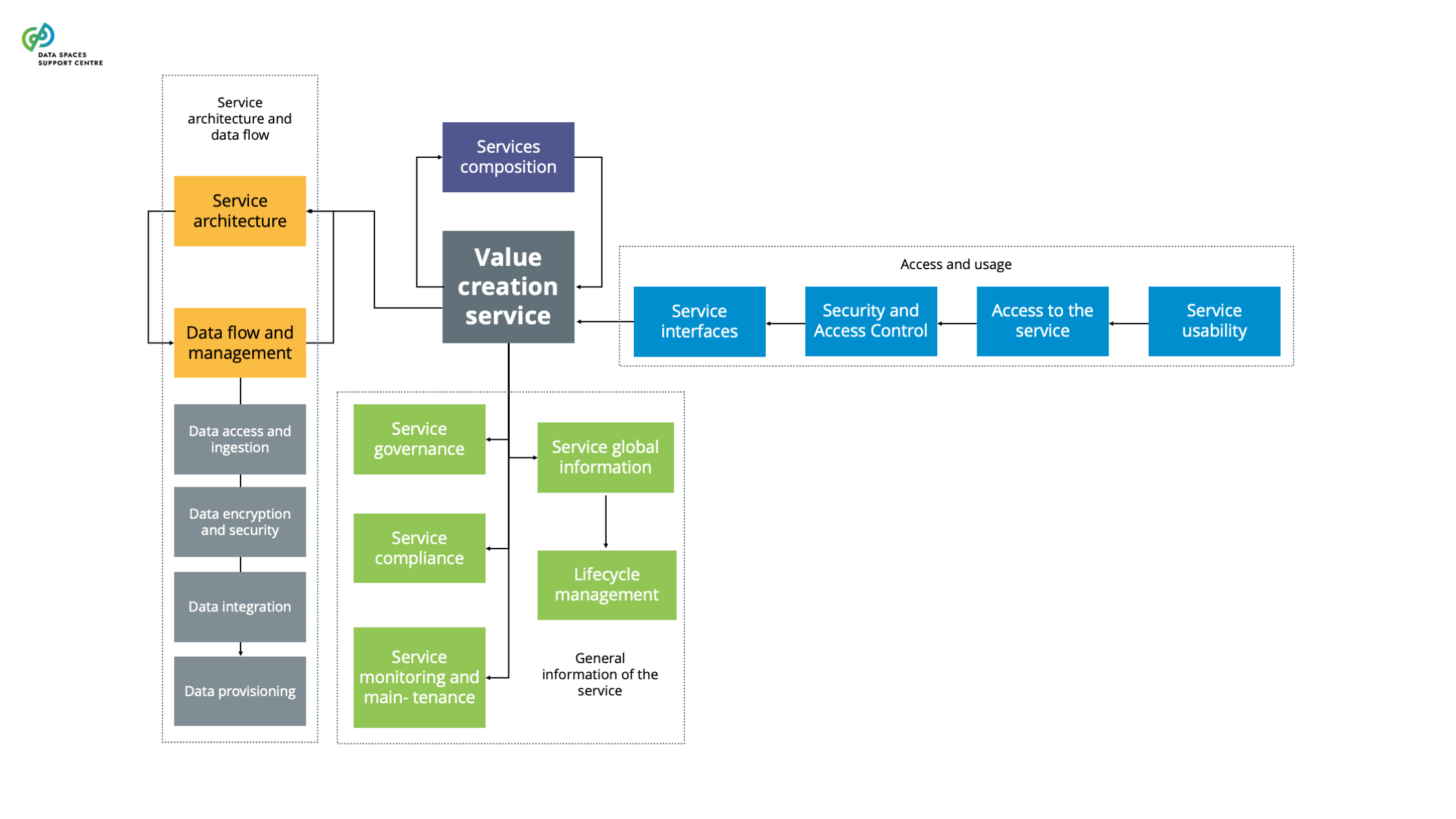
| Deployment And Use Of Services
Source (vsn) : Value creation services (bv20)
|
Deployment models suitable for the data space, depending on objectives, scalability and operational requirements (cloud-native architectures, hybrid cloud solutions, in-premises, serverless deployment)Define and adhere to Service Level Agreements that specify service availability, performance metrics, and support response times. Consider the SLA baseline of the specific service.Intuitive user interfaces (UI) and user experience design to make services easy to use and navigate |
| Development Cycle
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
The sequence of stages that a data space initiative passes through during its progress and growth. In each stage, the initiative has different needs and challenges, and when progressing through the stages, it evolves regarding knowledge, skills and capabilities. |
| Development Processes
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A set of essential processes the stakeholders of a data space initiative conduct to establish and continuously develop a data space throughout its development cycle.
Note : This term was automatically generated as a synonym for: data-space-development-processes
|
| Digital Europe Programme
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
An EU funding programme that funds several data space related projects, among other topics. The programme is focused on bringing digital technology to businesses, citizens and public administrations. |
| DMA Gatekeeper
Source (vsn) : Regulatory Compliance (bv20)
|
an undertaking providing core platform services, designated by the European Commission if:
it has a significant impact on the internal market;it provides a core platform service which is an important gateway for business users to reach end users; andit enjoys an entrenched and durable position, in its operations, or it is foreseeable that it will enjoy such a position in the near future (art. 3 (1) DMA). An undertaking shall be presumed to satisfy the respective requirements in paragraph 1:
as regards paragraph 1, point (a), where it achieves an annual Union turnover equal to or above EUR 7,5 billion in each of the last three financial years, or where its average market capitalisation or its equivalent fair market value amounted to at least EUR 75 billion in the last financial year, and it provides the same core platform service in at least three Member States;as regards paragraph 1, point (b), where it provides a core platform service that in the last financial year has at least 45 million monthly active end users established or located in the Union and at least 10 000 yearly active business users established in the Union, identified and calculated in accordance with the methodology and indicators set out in the Annex;as regards paragraph 1, point (c), where the thresholds in point (b) of this paragraph were met in each of the last three financial years. (art. 3 (2) DMA).
|
| DSSC Asset
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A sustainable open resource that is developed and governed by the Data Spaces Support Centre. The assets can be used to develop, deploy and operationalise data spaces and to enable knowledge sharing around data spaces. The DSSC also develops and executes strategies to provide continuity for the main assets beyond the project funding. |
| DSSC Glossary
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A limited set of data spaces related terms and corresponding descriptions. Each term refers to a concept, and the term description contains a criterion that enables people to determine whether or not something is an instance (example) of that concept. |
| DSSC Toolbox
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A catalogue of data space component implementations curated by the Data Space Support Centre. |
| Dynamic Capabilities (7)
Source (vsn) : Examples (bv20)
|
The governance authority is in constant discussion with the service providers and gives feedback on whether it is necessary to alter or change the business model.The board looks for ways in which to break even. There is no structural process in place to evaluate and monitor the business model.No structural process for innovating the business model is in placeThere is a board and a supervisory board, and there are three documents which define the governance of the data space:Statutes or Articles of Association of SCSNAccession AgreementCode of Conduct |
| EIDAS 2 Regulation
Source (vsn) : Identity & Attestation Management (bv30)
|
It is an updated version of the original eIDAS regulation, which aims to further enhance trust and security in cross-border digital transactions with the EU. |
| EIDAS Regulation
Source (vsn) : Identity & Attestation Management (bv30)
|
The EU Regulation on electronic identification and trust services for electronic transactions in the internal market |
| Enabling Services
Source (vsn) : 4 Data Space Services (bv30)
|
Refer mutually to facilitating services and participant agent services, hence the technical services that are needed to enable trusted data transaction in data spaces. |
| European Data Innovation Board
Source (vsn) : 11 Foundation of the European Data Economy Concepts (bv20)
|
The expert group established by the Data Governance Act (DGA) to assist the European Commission in the sharing of best practices, in particular on data intermediation, data altruism and the use of public data that cannot be made available as open data, as well as on the prioritisation of cross-sectoral interoperability standards, which includes proposing guidelines for common European data spaces (DGA Article 30 ). The European Data Innovation Board (EDIB) will have additional competencies under the Data Act. |
| European Data Innovation Board
Source (vsn) : 11 Foundation of the European Data Economy Concepts (bv30)
|
The expert group established by the Data Governance Act (DGA) to assist the European Commission in the sharing of best practices, in particular on data intermediation, data altruism and the use of public data that cannot be made available as open data, as well as on the prioritisation of cross-sectoral interoperability standards, which includes proposing guidelines for Common European Data Spaces (DGA Article 30 ). The European Data Innovation Board received additional additional assignments under the Data Act (DA Article 42 ). |
| European Digital Identification (EUDI) Wallet
Source (vsn) : Identity & Attestation Management (bv30)
|
The European Digital Identity Regulation introduces the concepts of EU Digital Identity Wallets. They are personal digital wallets that allow citizens to digitally identify themselves, store and manage identity data and official documents in electronic format. These documents may include a driving licence, medical prescriptions or education qualifications. |
| European Single Market For Data
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
A genuine single market for data – open to data from across the world – where personal and non-personal data, including sensitive business data, are secure and businesses also have easy access to high-quality industrial data, boosting growth and creating value.
Explanatory Text : Source: European strategy for data
|
| European Strategy For Data
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
A vision and measures ( a strategy ) that contribute to a comprehensive approach to the European data economy, aiming to increase the use of, and demand for, data and data-enabled products and services throughout the Single Market. It presents the vision to create a European single market for data. |
| Evidence
Source (vsn) : Trust Framework (bv30)
|
Evidence can be included by an issuer to provide the verifier with additional supporting information in a verifiable credential (ref. Verifiable Credentials Data Model v2.0 (w3.org) ) |
| Exploratory Stage
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
The stage in the development cycle in which a data space initiative starts. Typically, in this stage, a group of people or organisations starts to explore the potential and viability of a data space. The exploratory activities may include, among others, identifying and attracting interested stakeholders, collecting requirements, discussing use cases or reviewing existing conventions or standards. |
| Facilitating Services
Source (vsn) : 4 Data Space Services (bv30)
|
Services which facilitate the interplay of participants in a data space, enabling them to engage in (commercial) data-sharing relationships of all sorts and shapes.
Explanatory Text : They are sometimes also called ‘federation services’.
|
| FAIR Principles
Source (vsn) : Regulatory Compliance (bv20)
|
a collection of guidelines by which to improve the Findability, Accessibility, Interoperability, and Reusability of data objects. These principles emphasize discovery and reuse of data objects with minimal or no human intervention (i.e. automated and machine-actionable), but are targeted at human entities as well ( Common Fund Data Ecosystem Documentation) .
Explanatory Text : In 2016, the ‘FAIR Guiding Principles for scientific data management and stewardship’ were published in Scientific Data. The authors intended to provide guidelines to improve the Findability, Accessibility, Interoperability, and Reuse of digital assets. The principles emphasise machine-actionability (i.e., the capacity of computational systems to find, access, interoperate, and reuse data with none or minimal human intervention) because humans increasingly rely on computational support to deal with data as a result of the increase in volume, complexity, and creation speed of data (GO FAIR Initiative)
|
| Federated Data Spaces
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
A data space that enables seamless data transactions between the participants of multiple data spaces based on agreed common rules, typically set in a governance framework.
Explanatory Texts :
- The definition of a federation of data spaces is evolving in the data space community.
- A federation of data spaces is a data space with its own governance framework, enabled by a set of shared services (federation and value creation) of the federated systems, and participant agent services that enable participants to join multiple data spaces with a single onboarding step.
|
| Federation Services
Source (vsn) : 4 Data Space Services (bv20)
|
Services which facilitate the interplay of participants in a data space, enabling them to engage in (commercial) data-sharing relationships of all sorts and shapes. They perform an intermediary role in the data space. |
| Finite Data
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
Data that is defined by a finite set, such as a fixed dataset. |
| First-party Conformity Assessment Activity
Source (vsn) : Identity & Attestation Management (bv30)
|
conformity assessment activity that is performed by the person or organization that provides or that is the object of conformity assessment (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Functionality
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A specified set of tasks that are critical for operating a data space and that can be associated with one or more data space roles.
Explanatory Text : The data space governance framework specifies the data space functionalities and associated roles. Each functionality and associated role consist of rights and duties for performing tasks related to that functionality.
Note : This term was automatically generated as a synonym for: data-space-functionality
|
| Gatekeepers
Source (vsn) : Types of Participants (Participant as a Trigger) (bv20)
|
The Digital Markets Act defines gatekeepers as undertakings providing so-called “core platform services”, such as online search engines, social networking services, video-sharing platform services, number-independent interpersonal communications services, operating systems, web browsers, etc. According to Art. 3 (1) DMA, for an undertaking to be designated by the European Commission as a “gatekeeper”, it has to have a significant impact on the internal market; provide a core platform service which is an important gateway for business users to reach end users; and it enjoys an entrenched and durable position in its operations, or it is foreseeable that it will enjoy such a position in the near future. It also has to meet the requirements regarding an annual turnover above the threshold determined by the regulation. So far, the European Commission has designated the following gatekeepers: Alphabet, Amazon, Apple, Booking, ByteDance, Meta, and Microsoft. This position is determined in relation to a specific core platform service (for instance, Booking has been designated a gatekeeper for its online intermediation service “ http://Booking.com ” ). While the DMA does not aim to establish a framework for data sharing, it challenges the “data monopoly” of gatekeepers. Specific data-related obligations addressed to gatekeepers that may be relevant in the context of a data space include:Ban on data combination - For example, combining personal data from one core platform service with personal data from any further core platform services, or from any other services provided by the gatekeeper or with personal data from third-party services (art. 5(2) (b) DMA);Data silos - Prohibition to use, in competition with business users, not publicly available data generated or provided by those business users in the context of their use of the relevant core platform services (art. 6(2) DMA);Data portability - Obligation to provide end users and third parties authorised by an end user with effective portability of data provided by the end user or generated through the activity of the end user in the context of the use of the relevant core platform service (Article 6(9) DMA);Access to data generated by users - Obligation to provide business users and third parties authorised by a business user access and use of aggregated/non-aggregated data, including personal data, that is provided for or generated in the context of the use of the relevant core platform services (Article 6(10) DMA);Access search data for online search engines - Providing online search engines fair, reasonable and non-discriminatory terms to ranking, query, click and view data in relation to free and paid search generated by end users on its online search engines (Article 6(11) DMA). More information about the data-sharing obligations of the gatekeepers can be found here: data_sharing_obligations_under_the_dma_-_challenges_and_opportunities_-_may24.pdf (informationpolicycentre.com) |
| General Terms & Conditions
Source (vsn) : Contractual Framework (bv20)
|
The general terms and conditions are an Agreement that contributes to providing legal enforceability to some elements of the governance framework (e.g., making compliance with a specific process mandatory) and makes it binding on all data space participants. In some cases, it can be part of the founding agreement or at least directly referenced by it.The general terms and conditions allow data spaces to regulate interactions at the data space level. They create and define the roles and responsibilities of the data space participants: the data space governance authority, data provider, data recipient, and service providers (data-related services, trust framework provider, management of identities, etc.). When a data space is established as a legal entity, the agreement may cover both the liability between the data space participants and the liability between the participant and the legal entity. The general terms and conditions can serve as the framework for data transactions, namely the interactions (rights, responsibilities, liabilities, and obligations) of the data transaction participants. They do so by introducing common elements (e.g., a limited set of standard clauses or typologies of licences—see further in the data transaction agreements section) to improve legal interoperability and reduce transaction costs, ultimately reducing complexity and the possibility of conflict. The areas that the general terms and conditions regulate at the data space level are (for example):Admission policy for data space participants. This describes whether new participants are accepted, the conditions and eligibility criteria that parties must meet to join a data space, the conditions to remain a data space participant, and the procedures for the removal of an existing participant. Data space participants join a data space by accepting the terms and conditions.Intellectual property policy. At a minimum, this would specify that none of these agreements should be construed as an assignment of IP rights; instead, non-exclusive licenses are granted. If new IP rights may emerge from collaboration (e.g., sui generis rights for databases), then clauses to regulate ownership of IP rights could be included.Data protection policy. This describes the data protection policy at a data space level, referring to the obligations of the data space as a controller when processing the data of the data space participants. Additionally, this policy may also include references to the potential role of data spaces as processors of personal data to be shared within the data space, identifying the corresponding responsibilities of the parties and the data space as prescribed by law. The data space may provide a technical framework that ensures the processing operations in the data space comply with GDPR by design and adherence to this framework can be made binding. Templates for Data Processing Agreements (e.g., iSHARE ) or Data Exchange Agreements (e.g., iSHARE ) can also be provided.Technical standards. These outline and/or enforce specific technical standards for participants in the data space. The general terms and conditions may also restrict the data models and formats to be used in the data space. Cybersecurity and risk management policies. These describe the rules and procedures for the protection of technology and information assets that need to be protected, along with other identified risks to the data space infrastructure or participants.Complaints policy and dispute resolution rules. These describe the rules and procedures for filing a complaint. Rules can also be included for resolving disputes between data space participants, including with the data space governing authority.The areas that the general terms and conditions regulate at the transaction level include (for example):Common elements in the terms and conditions of a data contract—Data spaces can coordinate and harmonise the terms and conditions of Data-Sharing Agreements and Service Agreements by introducing common elements (e.g., a limited set of data licenses or including only open data licenses) or prohibiting certain clauses (e.g., the inability to charge for the use of data). Examples of the agreement-specific clauses in the general terms and conditions are listed below. For conceptual clarity, we distinguish between the general terms that relate to the data space level and the data transaction level.  Agreement-specific clauses related to the data space levelDefinitions (defining the roles of data space participants as well as potential third parties)Role-specific conditions (rights and obligations corresponding to the role),ResponsibilitiesFees and costsConfidentialityIP rightsData protectionAccession policy (whether new data participants can join a data space, what eligibility criteria they need to meet, whether there is a maximum number of participants, etc.)Technical standards and commitments (technical standards with which a party has to comply to make transactions and activities in the data spaces)Cybersecurity and risk management policiesComplaints policy and dispute resolution rules Agreement-specific clauses related to the transaction levelGeneral conditions for data sharingStandardised licences model for data usage rights – the general terms and conditions may limit the choice of licence or offer data providers a limited set of standardised licences. Standardisation refers to limiting the number or content of clauses. The advantage of including standardised licences is the reduction of transaction costs and increased scalability of the data space. Examples of types of licences may include:No limitations (the data product can be used without restrictions)Resharing with data space participants/internal use onlyNon-commercial use onlyData enrichment before resharingData can be enriched with the data recipient’s own dataData can be enriched with data from othersData can be enriched with the data recipient’s own data before resharing on a non-commercial basisData can be enriched with data of others before resharing on a non-commercial basisAd hoc-licenses (as determined by the parties)Standardised terms and conditions for data products - the agreement establishes mandatory terms and conditions to be included in the data product contract. It ensures that transactions between data provider and user take place on the basis of common terms and conditions, reducing transaction costs and increasing legal interoperability between transactions. Any terms and conditions can be the object of standardisation, from clauses on fees to clauses related to the rights of third parties on data.Mechanisms to calculate fees (if applicable) Agreement-specific clauses related to the data space levelDefinitions (defining the roles of data space participants as well as potential third parties)Role-specific conditions (rights and obligations corresponding to the role),ResponsibilitiesFees and costsConfidentialityIP rightsData protectionAccession policy (whether new data participants can join a data space, what eligibility criteria they need to meet, whether there is a maximum number of participants, etc.)Technical standards and commitments (technical standards with which a party has to comply to make transactions and activities in the data spaces)Cybersecurity and risk management policiesComplaints policy and dispute resolution rules Agreement-specific clauses related to the transaction levelGeneral conditions for data sharingStandardised licences model for data usage rights – the general terms and conditions may limit the choice of licence or offer data providers a limited set of standardised licences. Standardisation refers to limiting the number or content of clauses. The advantage of including standardised licences is the reduction of transaction costs and increased scalability of the data space. Examples of types of licences may include:No limitations (the data product can be used without restrictions)Resharing with data space participants/internal use onlyNon-commercial use onlyData enrichment before resharingData can be enriched with the data recipient’s own dataData can be enriched with data from othersData can be enriched with the data recipient’s own data before resharing on a non-commercial basisData can be enriched with data of others before resharing on a non-commercial basisAd hoc-licenses (as determined by the parties)Standardised terms and conditions for data products - the agreement establishes mandatory terms and conditions to be included in the data product contract. It ensures that transactions between data provider and user take place on the basis of common terms and conditions, reducing transaction costs and increasing legal interoperability between transactions. Any terms and conditions can be the object of standardisation, from clauses on fees to clauses related to the rights of third parties on data.Mechanisms to calculate fees (if applicable) |
| General Terms And Conditions
Source (vsn) : Contractual Framework (bv30)
|
An agreement defining the roles, relationships, rights and obligations of data space participants. |
| Geoquerying
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
Query involving geographical boundaries
Explanatory Text : Data querying frequently needs to be restricted to a geographical area.
|
| Governance
Source (vsn) : Business Model (bv30)
|
A description of how a group of organizations (necessary for a data space) is managed, organised, and regulated by agreements and processes, as well as how the partners control and influence its evolution and performance over time.Due to the collaborative nature of a data space business model, governance of affiliated and non-affiliated actors can be seen as strongly complementary to the business model and other building blocks. |
| Governance Authority
Source (vsn) : 1 Key Concept Definitions (bv30)
|
The body of a particular data space, consisting of participants that is committed to the governance framework for the data space, and is responsible for developing, maintaining, operating and enforcing the governance framework.
Explanatory Texts :
- A ‘body’ is a group of parties that govern, manage, or act on behalf of a specific purpose, entity, or area of law. This term, which has legal origins, can encompass entities like legislative bodies, governing bodies, or corporate bodies.
- The data space governance authority does not replace the role of public regulation and enforcement authorities.
- Establishing the initial data space governance framework is outside the governance authority's scope and needs to be defined by a group of data space initiating parties.
- After establishment, the governance authority performs the governing function (developing and maintaining the governance framework) and the executive function (operating and enforcing the governance framework).
- Depending on the legal form and the size of the data space, the governance and executive functions of a data space governance authority may or may not be performed by the same party.
Note : This term was automatically generated as a synonym for: data-space-governance-authority
|
| Governance Authority
Source (vsn) : Provenance, Traceability & Observability (bv30)
|
A governance authority refers to bodies of a data space that are composed of and by data space participants responsible for developing and maintaining as well as operating and enforcing the internal rules.
Note : This term was automatically generated as a synonym for: data-space-governance-authority
|
| Governance Authority
Sources (vsn) :
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
The body of a particular data space, consisting of participants that are committed to the governance framework for the data space, and is responsible for developing, maintaining, operating and enforcing the governance framework.
Note : This term was automatically generated as a synonym for: data-space-governance-authority
|
| Governance Authority (dsga)
Source (vsn) : Participation Management (bv30)
|
The body of a particular data space, consisting of participants that is committed to the governance framework for the data space, and is responsible for developing, maintaining, operating and enforcing the governance framework.
Note : This term was automatically generated as a synonym for: data-space-governance-authority-dsga
|
| Governance Authority Bodies And Members (4)
Source (vsn) : Examples (bv20)
|
According to the foundational documents, the highest level of governance consists of one representative from the service providers, one from the manufacturing industry, one knowledge institute and one industry association.There should be at least one director. Previously, in-kind services were provided by a knowledge institute but are now outsourced.The owner of the data space is the sector association. Therefore, they exist to ensure the progression of the sector. |
| Governance Framework
Source (vsn) : 1 Key Concept Definitions (bv30)
|
The structured set of principles, processes, standards, protocols, rules and practices that guide and regulate the governance, management and operations within a data space to ensure effective and responsible leadership, control, and oversight. It defines the functionalities the data space provides and the associated data space roles, including the data space governance authority and participants.
Explanatory Texts :
- Functionalities include, e.g., the maintenance of the governance framework the functioning of the data space governance authority and the engagement of the participants.
- The responsibilities covered in the governance framework include assigning the governance authority and formalising the decision-making powers of participants.
- The data space governance framework specifies the procedures for enforcing the governance framework and conflict resolution.
- The operations may also include business and technology aspects.
Note : This term was automatically generated as a synonym for: data-space-governance-framework
|
| Guidelines For Common European Data Spaces
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
The Data Governance Act (DGA Article 30(h )) defines that the European Data Innovation Board will propose guidelines for common European data spaces. The guidelines shall address, among other things: (i) cross-sectoral standards for data sharing, (ii) counter barriers to market entry and avoiding lock-in effects and ensuring fair competition and interoperability, (iii) protection for lawful data transfers to third countries, (iv) non-discriminatory representation of relevant stakeholders in the governance of common European data spaces and (v) adherence to cybersecurity requirements. |
| HealthData@EU
Source (vsn) : Regulatory Compliance (bv20)
|
cross-border infrastructure for secondary use of electronic health data established by the European Health Data Space Regulation (art. 52 (2) EHDS). |
| High-risk AI System
Source (vsn) : Regulatory Compliance (bv20)
|
'AI system’ means a machine-based system that is designed to operate with varying levels of autonomy and that may exhibit adaptiveness after deployment, and that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments (Art. 3 (1) AIA). AI system shall be considered to be high-risk where both of the following conditions are fulfilled:
the AI system is intended to be used as a safety component of a product, or the AI system is itself a product, covered by the Union harmonisation legislation listed in Annex I; the product whose safety component pursuant to point (a) is the AI system, or the AI system itself as a product, is required to undergo a third-party conformity assessment, with a view to the placing on the market or the putting into service of that product pursuant to the Union harmonisation legislation listed in Annex I (art. 6 (1); art. 6 (2) AIA).
Explanatory Texts :
- In addition to the high-risk AI systems referred above, AI systems referred to in Annex III shall be considered to be high-risk, such as:
- biometrics, in so far as their use is permitted under relevant Union or national law;
- critical infrastructures (e.g. transport), that could put the life and health of citizens at risk;
- educational or vocational training, that may determine the access to education and professional course of someone’s life (e.g. scoring of exams);
- safety components of products (e.g. AI application in robot-assisted surgery);
- employment, management of workers and access to self-employment (e.g. CV-sorting software for recruitment procedures);
- essential private and public services (e.g. credit scoring denying citizens opportunity to obtain a loan);
- law enforcement that may interfere with people’s fundamental rights (e.g. evaluation of the reliability of evidence);
- migration, asylum and border control management (e.g. automated examination of visa applications);
- administration of justice and democratic processes (e.g. AI solutions to search for court rulings).
|
| High-Value Datasets (HVDs)
Source (vsn) : Types of data (Data as a Trigger) (bv20)
|
High-Value Datasets (HVDs) are defined in the Open Data Directive as “documents held by a public sector body, the reuse of which is associated with important benefits for society, the environment and the economy”.HVDs can be re-usable for any purpose (as is the case for open data).Public sector bodies are not allowed to charge fees for the reuse of HVDs.In the context of data transactions within a data space, it is important to remember that the reuse of documents should not be subject to conditions, but some cases are justified by a public interest objective. In these situations, public sector bodies might issue a license imposing conditions on the reuse by the licensee dealing with issues such as liability, the protection of personal data, the proper use of documents, guaranteeing non-alteration and the acknowledgement of source. In addition to the above, there are categories of data for which we do not know the legal status of the data. Therefore, they are de facto under the control of the data holder. |
| High-Value Datasets (HVDs)
Source (vsn) : Regulatory Compliance (bv20)
|
data held by a public sector body associated with important benefits for society, the environment, and the economy when reused (Open Data Directive). The thematic categories of high-value datasets are: geospatial data; earth observation and environment data; meteorological data; statistics; companies and company ownership data; mobility data (Annex I, Open Data Directive).
Explanatory Text : These datasets are suitable for creating value-added services, applications, and new jobs, and are made available free of charge in machine-readable format documents, the reuse of high-value datasets is associated with important benefits for the society and economy. They are subject to a separate set of rules ensuring their availability free of charge, in machine readable formats. They are provided via Application Programming Interfaces (APIs) and, where relevant, as a bulk download. The thematic scope of high-value datasets is provided in an Annex to the Directive.
|
| Holder
Source (vsn) : Identity & Attestation Management (bv30)
|
A role an entity might perform by possessing one or more verifiable credentials and generating verifiable presentations from them. A holder is often, but not always, a subject of the verifiable credentials they are holding. Holders store their credentials in credential repositories . (ref. Verifiable Credentials Data Model v2.0 (w3.org) ) |
| Horizon Europe Programme
Sources (vsn) :
- 11 Foundation of the European Data Economy Concepts (bv20)
- 11 Foundation of the European Data Economy Concepts (bv30)
|
An EU funding programme that funds data space related research and innovation projects, among other topics. |
| Identifying And Monitoring Use Case Scenarios
Source (vsn) : Use Case Development (bv20)
|
Collecting ideas for use case scenarios through activities such as observing potential customers’ needs and analysing other data spaces and platforms. |
| Identifying And Tracking Use Case Scenarios
Source (vsn) : Use Case Development (bv30)
|
Collecting ideas for use case scenarios through activities such as observing potential users’ needs and analysing other data spaces and platforms. |
| Identity
Source (vsn) : Identity & Attestation Management (bv30)
|
an Identity is composed of a unique Identifier , associated with an attribute or set of attributes that uniquely describe an entity within a given context and policies determining the roles, permissions, prohibitions, and duties of the entity in the data space |
| Implementation Of A Component
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
The result of translating/converting a data space component into a functional and usable artefact, such as executable code or other tool.
Note : This term was automatically generated as a synonym for: implementation-of-a-data-space-component
|
| Implementation Of A Data Space Component
Sources (vsn) :
- 9 Building Blocks and Implementations (bv20)
- 9 Building Blocks and Implementations (bv30)
|
The result of translating/converting a data space component into a functional and usable artefact, such as executable code or other tool. |
| Implementation Stage
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
The stage in the development cycle that starts when a data space initiative has a sufficiently detailed project plan, milestones and resources (funding and other) for developing its governance framework and infrastructure in the context of a data space pilot. It is typical for this stage that the parties involved in the pilot and the value created for each are also clearly identified. |
| Implementing Use Cases
Sources (vsn) :
- Use Case Development (bv20)
- Use Case Development (bv30)
|
Implementing use cases both from organisational and business perspectives (e.g., agreements) and from technical perspectives (e.g., vocabularies, APIs, connectors). |
| Information Model
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A classification scheme used to describe, analyse and organise a data space initiative according to a defined set of questions.
Note : This term was automatically generated as a synonym for: data-spaces-information-model
|
| Infrastructure (deprecated Term)
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A technical, legal, procedural and organisational set of components and services that together enable data transactions to be performed in the context of one or more data spaces.
Explanatory Text : This term was used in the data space definition in previous versions of the Blueprint. It is replaced by the governance framework and enabling services, and may be deprecated from this glossary in a future version.
Note : This term was automatically generated as a synonym for: data-space-infrastructure-deprecated-term
|
| Initiative
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A collaborative project of a consortium or network of committed partners to initiate, develop and maintain a data space.
Note : This term was automatically generated as a synonym for: data-space-initiative
|
| Intellectual Property Rights/ Trade Secret-Protected Data(sets)
Source (vsn) : Types of data (Data as a Trigger) (bv20)
|
Intellectual property (IP) law can confer rights over datasets, often through copyright and the sui generis database right. Data may also be protected by trade secrets, which constitute a separate legal regime. It is the responsibility of each data space participant to ensure legal compliance and to have an authorisation and/or legal basis for data sharing if data is protected by copyright, sui generis or trade secrets. Copyright law:Protects creative works like text, images, video, and sound. It also protects software (e.g., source code) and databases (e.g., a collection of independent data protected). Copyright does not protect data itself - it differs from other works, which are protected due to specific qualifying conditions, such as being an author’s original creation.To be protected by copyright, a database has to be original, reflect the author's intellectual creation, and be fixed in tangible form. In the context of databases, a specific test of originality reflecting the special characteristic of databases is required (whether the selection or arrangement of their contents constitutes the author’s own intellectual creation).Purely factual information is usually not eligible for protection (Article 2, InfoSoc Directive ).Sui Generis Database Right ( EU Database Directive 96/9/EC ):Databases could be protected by the sui generis database right in addition to copyright protection.Grants sui generis database rights to creators who made qualitatively and/or quantitatively substantial investment in obtaining, verifying, or presenting contents.Provides right to prevent unauthorized extraction or re-utilisation.Defines databases as collections arranged systematically and individually accessible.Trade Secret Protection ( EU Trade Secrets Directive 2016/943 ):Encompasses various data types, requiring secrecy and commercial value.Enforceable rights against unlawful use and misappropriation without conferring property rightsSecrecy is preserved as long as persons having access to information are bound by confidentiality agreements.Solutions to be implemented on a data space levelThe acknowledgement of intellectual property and quasi-IP rights (trade secrets), both for identifying existing assets and creating new ones, should be addressed in the intellectual property policy within the general terms & conditions and the intellectual property clauses of particular data product contracts. More details can be found in the Contractual Framework building block.Data holders are responsible for providing information about the IP rights and/or trade secrets they possess over particular datasets before sharing them with potential data recipients.Specific legal provisions concerning trade secrets’ aspects in the context of data sharing can be found in the Data Act (primarily in the context of business-to-consumer and business-to-business data sharing).Examples of possible legal, organisational and technical measures to preserve intellectual property rights or trade secrets can be found in the recently adopted European Health Data Space Regulation. Such measures could include data access contractual arrangements, specific obligations in relation to the rights granted to the data recipient, or pre-processing the data to generate derived data that protects a trade secret but still has utility for the user or configuration of the secure processing environment so that such data is not accessible by the data recipient (recital 60, art. 53 EHDS-R ) . |
| Intermediary
Source (vsn) : 4 Data Space Services (bv30)
|
Service provider who provides an enabling service or services in a data space. In common usage interchangeable with ‘operator'. |
| Intermediary
Sources (vsn) :
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
|
A data space intermediary is a service provider who provides an enabling service or services in a data space. In common usage interchangeable with ‘operator'.
Note : This term was automatically generated as a synonym for: data-space-intermediary
|
| Interoperability
Source (vsn) : 7 Interoperability (bv30)
|
The ability of participants to seamlessly exchange and use data within a data space or between two or more data spaces.
Explanatory Texts :
- Interoperability generally refers to the ability of different systems to work in conjunction with each other and for devices, applications or products to connect and communicate in a coordinated way without effort from the users of the systems. On a high-level, there are four layers of interoperability: legal, organisational, semantic and technical (see the European Interoperability Framework [EIF]).
- Legal interoperability: Ensuring that organisations operating under different legal frameworks, policies and strategies are able to work together.
- Organisational interoperability: The alignment of processes, communications flows and policies that allow different organisations to use the exchanged data meaningfully in their processes to reach commonly agreed and mutually beneficial goals.
- Semantic interoperability: The ability of different systems to have a common understanding of the data being exchanged.
- Technical interoperability: The ability of different systems to communicate and exchange data.
- Also the ISO/IEC 19941:2017 standard [20] is relevant here.
- Note: As per Art. 2 r.40 of the Data Act: ‘interoperability’ means the ability of two or more data spaces or communication networks, systems, connected products, applications, data processing services or components to exchange and use data in order to perform their functions. We describe this wider term as cross-data space interoperability.
Note : This term was automatically generated as a synonym for: data-space-interoperability
|
| Interoperability (DA)
Source (vsn) : Regulatory Compliance (bv20)
|
means the ability of two or more data spaces or communication networks, systems, connected products, applications, data processing services or components to exchange and use data in order to perform their functions (art. 2 (40) DA). |
| Intra- Interoperability
Source (vsn) : 7 Interoperability (bv30)
|
The ability of participants to seamlessly access and/or exchange data within a data space. Intra-data space interoperability addresses the governance, business and technical frameworks (including the data space protocol and the data models) for individual data space instances.
Note : This term was automatically generated as a synonym for: intra-data-space-interoperability
|
| Intra-data Space Interoperability
Source (vsn) : 7 Interoperability (bv30)
|
The ability of participants to seamlessly access and/or exchange data within a data space. Intra-data space interoperability addresses the governance, business and technical frameworks (including the data space protocol and the data models) for individual data space instances. |
| IoT Data
Source (vsn) : Types of data (Data as a Trigger) (bv20)
|
The Data Act lays down a harmonised framework specifying the rules for using product data or related service data, including data from Internet of Things devices, smartphones, and cars. It imposes the obligation on data holders to make data available to users and third parties of the user’s choice in certain circumstances. It also ensures that data holders make data available to data recipients in the Union under fair, reasonable and non-discriminatory terms and conditions and in a transparent manner. These provisions apply to the data of specific origin, irrespective of the personal/non-personal character of the data. If the processing of personal data is involved, it is important to remember that the GDPR still applies.Data spaces should pay attention to Chapter II of the Data Act, especially in the context of data transactions involving the processing of product data and related service data. More specifically, data spaces should consider the rights of the users of connected products or related services that they hold towards the data they produce by using these products or services. These rights include access to and use of the data for any lawful purpose. There are some exceptions to access rights (for example, if the data user requests access to personal data of which he is not a data subject). The data provided to the user should be of the same quality as the data available to the data holder and should be provided easily, securely, free of charge, and in a comprehensive, structured, commonly used and machine-readable format. If the data transaction is supposed to be concluded without the data user directly involved, it is important to remember that the scope of such transactions is predefined by the contract with the user. Data holders shall not make available non-personal product data to third parties for commercial or non-commercial purposes other than the fulfilment of such a contract.Data holders can also decide to make their data available via a third parties of their choice (for example, data intermediation service providers as defined by the DGA) for commercial purposes. These third parties hold then certain obligations towards the data they receive on behalf of the user. For example, they should be able to transfer the data access rights granted by the user to other third parties, including in exchange for compensation. Data intermediation services may support users or third parties in establishing commercial relations with an undetermined number of potential counterparties for any lawful purpose falling within the scope of the Data Act, providing that users remain in complete control of whether to provide their data to such aggregation and the commercial terms under which their data are to be used. |
| Issuer
Sources (vsn) :
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
A role an entity can perform by asserting claims about one or more subjects , creating a verifiable credential from these claims , and transmitting the verifiable credential to a holder . (ref. Verifiable Credentials Data Model v2.0 (w3.org) ) |
| LOTL (List Of Trusted Lists)
Source (vsn) : Trust Framework (bv30)
|
List of qualified trust service providers in accordance with the eIDAS Regulation published by the Member States of the European Union and the European Economic Area (EU/EEA) |
| Machine-Readable Policy
Source (vsn) : Access & Usage Policies Enforcement (bv30)
|
A policy expressed in a standard format (ODRL) that computers can automatically process, evaluate, and enforce. |
| Maintenance
Source (vsn) : Value creation services (bv20)
|
Regular maintenance schedule for updatesVersion control for all service componentsBack-up and recovery |
| Maturity Model
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
Set of indicators and a self-assessment tool allowing data space initiatives to understand their stage in the development cycle, their performance indicators and their technical, functional, operational, business and legal capabilities in absolute terms and in relation to peers.
Note : This term was automatically generated as a synonym for: data-space-maturity-model
|
| Membership Credential
Source (vsn) : Identity & Attestation Management (bv30)
|
credential issued by the Data Space Governance Authority after having assessed compliance of an entity to its rules. This credential attest participation in a data space. |
| Meta-standard
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A standard designed to define or annotate data models within a particular domain or across multiple domains. These meta-standards provide a framework or guidelines for creating and annotating other standards (data models), ensuring consistency, interoperability, and compatibility. |
| Multi-Sided Business Model
Source (vsn) : Business Model (bv30)
|
A business model is said to be multi-sided if an organization serves different segments, and those segments also interact. An example is Airbnb, where apartments are offered to travellers. This is also referred to as a ‘platform business model’.A data space differs in two important ways from a platform business model: In order to establish sovereignty and avoid undesired ‘winner-takes-all’ effects, control of the sharing of data essentially lies with the data owner and the infrastructure is distributed. |
| Network Effects (8)
Source (vsn) : Examples (bv20)
|
End-users get more out of their subscription to SCSN once more customers and/or suppliers join the network, as they can automate a larger part of their purchase-to-pay process through SCSN.
Service providers enhance the appeal of their services with a larger network to connect to, increasing savings for their clients.
The expansion strategy is mainly aimed at the service providers adding end-users through their client base and connecting them to SCSN. |
| Network Of Stakeholders
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
The group of parties relevant to the development of data spaces and with whom the Data Spaces Support Centre proactively engages in achieving its purpose and objectives. The community of practice is the core subset of this network of stakeholders and the primary focus group for the DSSC. |
| Non-Finite Data
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
Data that is defined by an infinite set or has no specified end, such as continuous streams. |
| Non-personal Data
Source (vsn) : Types of data (Data as a Trigger) (bv20)
|
WARNING: This term was created, but not actually defined by the source.
|
| Non-personal Data
Source (vsn) : Regulatory Compliance (bv20)
|
data other than personal data;( DGA Article 2(4) ) |
| Non-Provenance Traceability
Source (vsn) : Provenance & Traceability (bv20)
|
All other traceability data useful for other then provenance data. |
| Notary
Source (vsn) : Trust Framework (bv30)
|
Notaries are entities accredited by the Data Space, which perform validation based on objective evidence from a data space Trusted Data source, digitalising an assessment previously made. |
| Object Of Conformity Assessment
Source (vsn) : Identity & Attestation Management (bv30)
|
entity to which specified requirements apply (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Observability
Source (vsn) : Provenance, Traceability & Observability (bv30)
|
The ability to monitor, measure and understand the internal states of processes through its outputs such as logs, metrics and traces. |
| Observability Services
Source (vsn) : Provenance & Traceability (bv20)
|
A service that stores the audit data of data sharing transactions within the data space and provide services related to observability. |
| Offboarding
Source (vsn) : Participation Management (bv20)
|
Reasons for Offboarding Different reasons for offboarding exist. In the regular case that a participant simply wants to exit the data space, the structured way of offboarding, described below applies. A different reason might be the forced exit, caused e.g. by the participant not complying with the data spaces rules. In such a case, the Data Space Governance Authority needs to formulate rules and processes of how to enforce an exit. Another scenario is the exception handling when a participating company e.g. goes bankrupt and cannot fulfill its obligations anymore. In such a case, the Data Space Governance Authority needs to inform all affected parties and enforce the exit.A general overview of the onboarding and offboarding process in a data space is depicted in Figure 1. Offboarding process Offboarding participants requires careful consideration of obligations and responsibilities toward the data space and other participants. The governance framework, especially its Terms and Conditions, guides the exit process, ensuring a smooth transition while safeguarding the interests of all involved parties. The offboarding process is designed to uphold the integrity and continuity of the data space by addressing issues such as data rights/holdings, data transfer, and termination of access. Exiting the data space requires proof that all contracts made with other participants have been fulfilled and no contractual obligations remain open. Accordning to the General Terms and Conditions, the participant informs the Data Space Governance Authority about the desired exit of the data space. However it is stated in the Terms and Conditions, this can be realized digitally or in a written form. After checking whether all offboarding criteria are met, the Data Spaces Governance Authority confirms the exit to the participant.Elements that ensure careful and efficient offboarding are:Documention of exit procedures: Establishing and following a documented offboarding procedure that helps to ensure consistency and completeness in the process. This documentation should include detailed steps for data transfer, access termination, and contract closure. This entails for instance a continous life cycle management of credentials, such as defined in the Identity and Attestation building block.Data Transfer and Deletion Protocols: Implementing clear protocols for the secure transfer or deletion of data is essential. This includes ensuring that data is either transferred to another party or securely deleted, in accordance with the corresponding licenses agreed upon, but also with the data space policies and any applicable legal requirements.Notification: Providing timely and clear notifications to all relevant parties about the participant’s exit helps prevent misunderstandings and ensures that all stakeholders are aware of possible changes. This communication should include details about data transfer, access termination, and any remaining obligations.Verification of compliance: Conducting a thorough review to verify that all contractual and compliance obligations have been met before finalizing the offboarding process. This includes ensuring that any financial or legal obligations are settled and that all agreements with other participants are fulfilled.Offboarding support: Offering support during the transition period to address any issues or questions that may arise. This can include providing assistance with data transfer or answering queries about remaining obligations.Periodic Framework Reviews: Conducting periodic and thorough reviews of the data space governance framework and incorporating necessary updates in response to legislative changes helps ensure the ongoing sustainability and effectiveness of the data space ecosystem during the off- and onboarding process. |
| Offering
Sources (vsn) :
- Data Space Offering (bv20)
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
|
Data product(s), service(s), or a combination of these, and the offering description.
Explanatory Text : Offerings can be put to a catalogue.
|
| Offering
Source (vsn) : Publication and Discovery (bv30)
|
Data product(s), service(s), or a combination of these, and the offering description. Offerings can be put into a catalogue. |
| Offering Description
Sources (vsn) :
- Data Space Offering (bv20)
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
|
A text that specifies the terms, conditions and other specifications, according to which an offering will be provided and can be consumed.
Explanatory Texts :
- Offering descriptions contain all the information needed for a potential consumer to make a decision whether to consume the data product(s) and/or the service(s) or not.
- This may include information such as description, provider, pricing, license, data format, access rights, etc.
- The offering description can also detail the structure of the offering, how data products and services can be obtained, and applicable rights and duties.
- Typically offering descriptions are machine-readable metadata.
|
| Onboarding
Source (vsn) : Participation Management (bv20)
|
Efficient onboarding of participants is critical for a seamless functioning data space. It ensures that participants can quickly integrate into the data space while adhering to necessary compliance and technical standards. This process minimizes the risk of operational inefficiencies and potential data misuse, thus fostering a trustworthy and collaborative environment essential for a thriving data space ecosystem. The Data Space Governance Authority sets the minimum requirements for data space participation. This process involves defining General Terms and Conditions of the data space. These terms and conditions outline the rules for joining, ensuring a clear understanding of roles, responsibilities, and compliance requirements. This includes rules for proving identity, as well as how attestations are issued (first-, second-, or third-party). The terms and conditions clearly need to cover all relevant rules and regulations such as admission policies, technical standards, data protection policies, but also offboarding regulations. The level of rules and requirements for joining and participating in a data space might vary depending on several factors. As further described in the Regulatory Compliance building block, for example, some domains might require more stringent rules than others. Also, the type of data handled within the data space calls for different rules. In case the data space handles for instance personal data, the rules and requirements for participating in the data space need to be in line with all relevant legal provisions, such as the GDPR.The General Terms & Conditions must hence clearly formulate the requirements for joining, which are specified in the conformity schema of the data space’s governance framework. Adhering to stringent rules can raise the bar for potential data providers to participate. The way rules are made in a data space affects how data transactions work. This is closely tied to the data space's purpose and mission. A data space can introduce additional internal rules and policies, as necessary for its functionality. While introducing such additional rules, it should avoid creating unnecessary hurdles for participation in the data space and contribute to smooth its functioning.Since reasons for joining a data space vary (business interest, legal requirements etc.), the Data Space Governance Authority must ensure that the data space is discoverable for interested parties (or candidates) and that General Terms and Conditions are accessible and understandable for them.Onboarding is linked to pre- and post-conditions which are essential to ensure smooth and secure operation. Pre-conditions Admission policies within the General Terms and Conditions describe the conditions and eligibility criteria that third parties need to meet in order to join a data space. This entails identity verification, compliance check, technical requirements, access control setup, data quality standards or security policies. Once the candidate agrees to the General Terms and Conditions and meets all admission criteria, a process for accepting the General Terms and Conditions needs to be implemented. This can be realized by e.g. mutually signing an agreement or by letting the participant accept the General Terms and Conditions digitally. The form of accepting the General Terms and Conditions depends on the role (transaction party, service provider etc.) a candidate wants to take in the data space.. The General Terms and Conditions should include requirements for verifying participants (e.g., strong identification) and setting requirements for the products and services available in the data space (e.g., language, data formats, etc.). The Data Space Governance Authority must balance lowering barriers to entry (flexible rules) and promoting interoperability and data quality (strict rules). Depending on the Governance Framework of the data space, the Data Space Governance Authority must provide mechanisms to check if all admission/eligibility criteria are fulfilled by the candidate. To join the data space, the candidate submits an application, detailling the role and intended use of the data space to the Data Space Governance Authority, which in turn reviews the applicant’s compliance with legal, technical, and operational standards, ensuring they meet all conditions. Alternatively, the Data Space Governance Authority can decide to refrain from an application process, but grant access to every participant that accepts the General Terms and Conditions and meets all conditions. Both options require constant monitoring that all participants act in accordance to the data spaces' rules and obligations. In both cases, the candidate needs to receive a notification once the Data Space Governance Authority decides on the application status.In cases where the Data Space Governance Authority decides on denying access, the applicant should be informed about reasons.As described in the Identity and Attestation building block, upon approval, access credentials are issued, enabling participants to interface with the data space. The Data Space Registry, managed by the Data Space Governance Authority, supports the onboarding process by listing data space rules, Trust Anchors, but also conformity schemes formulated to assess compliance. The latter should be described in the data space’s Rulebook. Post-conditions Successful integration is realized with verified access to the necessary data and resources with ensured technical interoperability. Technical onboarding by the Data Space Governance Authority is a process to enable new participants a seamless connection and instant readiness to actively engage in the data space. This can be for instance aided with initial data integration support by the Data Space Governance Authority to ensure data or services meet quality format and standards.Active monitoring extends beyond initial onboarding, with continuous oversight to ensure participants adhere to data space policies and standards. This ongoing monitoring helps identify areas where the onboarding process can be improved, ensuring that the data space evolves to meet participant needs and emerging challenges. Feedback from participants is crucial in this process, enabling the Data Space Governance Authority to make data-driven adjustments to onboarding procedures, enhancing both security and participant satisfaction. |
| Ontology
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A data model that defines knowledge within and across domains by modelling information objects and their relationships, often expressed in open metamodel standards like OWL, RDF, or UML. |
| Operational Processes
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A set of essential processes a potential or actual data space participant goes through when engaging with a functioning data space that is in the operational stage or scaling stage. The operational processes include attracting and onboarding participants, publishing and matching use cases, data products and data requests and eventually data transactions.
Note : This term was automatically generated as a synonym for: data-space-operational-processes
|
| Operational Stage
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
The stage in the development cycle that starts when a data space initiative has a tested implementation of infrastructure(s) and governance framework, and the first use case becomes operational (data flowing between data providers and data recipients and use case providing the intended value). |
| Operator
Source (vsn) : 4 Data Space Services (bv30)
|
Service provider that provides enabling services that are common to all participants of the data space. In common usage interchangeable with ‘intermediary’.
Explanatory Text : We use typically the term ‘operator’ when a single actor is assigned by the governance authority to manage the enabling services and when it is responsible for the operation of the data space, ensuring functionality and reliability as specified in the governance framework.
|
| Participant
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
- Participation Management (bv30)
|
A party committed to the governance framework of a particular data space and having a set of rights and obligations stemming from this framework.
Explanatory Text : Depending on the scope of the said rights and obligations, participants may perform in (multiple) different roles, such as: data space members, data space users, data space service providers and others as described in this glossary.
Note : This term was automatically generated as a synonym for: data-space-participant
|
| Participant Agent
Source (vsn) : 4 Data Space Services (bv30)
|
A technology system used to conduct activities in a data space on behalf of a party.
Explanatory Text : The participant agent can offer technical modules that implement data interoperability functions, authentication interfacing with trust services and authorisation, data product self-description, contract negotiation, etc. A ‘connector’ is an implementation of a participant agent service.
|
| Participant Agent Intermediary
Source (vsn) : 4 Data Space Services (bv20)
|
A party who provides participant agent services for the data space participants as defined by the data space governance framework. |
| Participant Agent Services
Source (vsn) : 4 Data Space Services (bv30)
|
Services to enable an individual participant to interact within the data space, facilitate the sharing (providing or using) of data, specify access and usage policies, and more.
Explanatory Text : The participant agent services provide operations on the control plane that are executing the data services on the data plane. The control plane and data plane should work together to manage the data transfer process. After contract negotiation, the technical transfer process can take place.
|
| Participants
Source (vsn) : Participation Management (bv20)
|
Participants in a data space comprise different entities. Data Providers are organizations that supply data to the data space. They generate and share data sets that can be used by others. Data Users consume data from the data space for various purposes such as analysis, decision-making or product development and therefore directly engage in the process of data transaction. For both types of participants, participation management needs to ensure the management of permissions, support of data quality standards, but also mechanisms to monitor and report data utilization. Intermediaries and Operators facilitate the exchange of data between providers and users. They enable and intermediate data exchange as (value creation) service providers. Even though they do not engage in data transactions, they are crucial participants to the data space, which is why participation management should facilitate data intermediaries and operators to ensure adherance of interoperability standards. Data Rights Holders are individuals or organizations that hold the rights to the data. They decide the terms and conditions under which their data can be shared and used within the data space. Data Space Governance Authorities might formulate more specific roles per data space, documented in the data space’s rulebook. Example: For some data spaces, distinguishing between participants who form the Data Space Governance Authority and those who do not, might be needed. Role differentiation could help in clarifying responsiblities, maintaining trust and transparency. So for instance, Data Space Members can be introduced as an additional role for organisations that found the data space, sign the founding agreements and create the Data Space Governance Authority. Note: to be considered additionally
External stakeholders are organizations not directly involved in the data space, but might significantly be affected by or having impact to the data space ecosystem. While they are not particularly participants of the data space, they might have interests and requirements that affect participation management and should therefore be taken into consideration, as well. This requires the data space governance authority to understand concerns and needs of external stakeholders and foster transparency by considering the potential impact and consequences of the data space on their activities. |
| Party
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A natural person or a legal person
Explanatory Text : Parties are organisations (enterprises, governmental bodies, not-for-profits) or human beings, i.e. entities that set their own objectives and that ‘sovereignly’ decide what they do and do not do.
|
| People, Resources And Activities (6)
Source (vsn) : Examples (bv20)
|
A director and several board members. Operations are outsourced to TNO and KPN.Cost Model: A director, operations are outsourced to TNO and KPN. |
| Performance, Monitoring And Logging
Source (vsn) : Value creation services (bv20)
|
Centralized monitoring system to collect, aggregate, and visualize performance metrics from all services and infrastructure componentsAlign with the provenance and traceability components of the data space for logs for services use, performance, access attempts, and configuration changes, incoprorating aggregation, search and visualization functionalitiesTools for real time monitorig and visualizationDefine global performance metrics Define Service Level Indicators (SLI) to measure the availability and performance of a service.Define Service Level Objectives (SLO) to guide internal process towards the Service Level Agreements. Regular reports on system performance, service usage, and security incidents |
| Permission
Source (vsn) : Regulatory Compliance (bv20)
|
giving data users the right to the processing of non-personal data; (Data Governance Act Article 2(6)) |
| Personal Data
Source (vsn) : Types of data (Data as a Trigger) (bv20)
|
Legal landscape relevant to personal data: The data protection legal framework, including the GDPR , as well as the Law Enforcement Directive and the e-Privacy Directive (if particular circumstances apply), remains fully applicable to the processing of personal data within the context of a data space, so that parties involved in the processing activities of personal data will need to ensure compliance with relevant legal provisions. Parties affected: Neither the involvement of a data space, nor that of a personal data intermediary, relinquishes the parties involved in such processing of their duties as data controllers or processors.The clear establishment of the roles of data controller and data (sub-)processor should also be a priority, taking into account the essential criterion of decision-making powers regarding purpose and means of processing. Continuous compliance: Issues of data protection should be an important consideration from the very start of the design of a data space and throughout all of its development stages.Applicability to data spaces: In the context of data spaces, the GDPR is highly (or most) relevant for use cases. For example, if a use case or transaction involves any information relating to an identified or identifiable natural person ('data subject'), the use case or data transaction participants will need to ensure compliance with data protection legislation, most notably the principles relating to the processing of personal data.The GDPR also applies to mixed datasets (comprised of both non-personal and personal data). This remains valid also if personal data represents only a small part of the dataset.The concept of the “purpose” under data protection law should be given particular attention, as it is fundamental to clearly define any personal data processing activity.Consideration of how to ensure accountability within a data space and how compliance with data protection principles, such as lawfulness, transparency, and purpose limitation, should be facilitated. Additional resources: The Spanish Data Protection Authority , in reference also to the EDPB-EDPS Joint Opinion 03/2022 on the Proposal for a Regulation on the European Health Data Space , highlights the importance of a data protection policy, which should state “how the principles and rights set out in the data protection regulation and the guidelines in this document are to be implemented in a concrete, practical and effective manner.” Spanish data protection authority: "Approach to data spaces from GDPR perspective"Some of the most important elements to be considered for a data protection policy that the Spanish Data Protection Authority lists in its report (p. 89-97) include the involvement of data protection officers (DPOs) and advisors in the design of data spaces; implementation of procedures for authorising the processing of personal data within the data space; a precise definition of the purposes of data processing; and risk management, including data protection impact assessments (DPIAs) coordinated between involved parties.Synthetic data (sometimes referred to as “fake data”) can be understood as data artificially generated from original data, preserving the statistical properties of said original data. Some data may also be completely artificially created without an underlying real-world data asset (e.g. virtual gaming environments). From a technical perspective, the primary purpose of its generation is to increase the amount of data. This solves an issue of insufficiency in datasets or improves the variability of available data. It also serves as a way to mitigate risks to the fundamental rights of individuals. According to the Spanish Data Protection Authority, the use of synthetic data, along with other techniques such as generalisation, suppression, or the use of Secure Processing Environments, can be the way to comply with data minimisation or privacy by design/default principles. It is important to remember that when personal data is being used to generate synthetic data, it will be considered part of a processing operation and, therefore, subject to compliance with the GDPR. However, depending on the original data, the model and additional techniques applied, the synthetic data can be anonymous data.The report also emphasizes the role of traceability in data spaces for providing control mechanisms relevant for the processing activities within data spaces. In that regard, data traceability should help to identify roles and implement access control and access logging policies. It should help to facilitate fulfilling particular objectives set by the GDPR, in particular addressing the transparency requirements to data subjects, enabling the effective exercise of data subjects’ rights, such as the management of consent, facilitating excercising the obligations of the controller (e.g., to ensure the principles of restriction of processing, purposes compliant with the legal bases or of processors/sub-processors), and allowing Supervisory Authorities to exercise their powers in accordance with Article 58(1) of the GDPR.More specifically, keeping of log of accesses and data space participants' actions performed within a data space could be a way to implement the obligations laid down by art. 32 (1) GDPR requiring from controller and processor the implementation of appropriate technical and organisational measures to ensure a level of security appropriate to the risk of varying likelihood and severity for the rights and freedoms of natural persons.To read more about Provenance and Traceability in data spaces, please check the Provenance and Traceability Building Block . Technical implementation: As part of the personal data protection arrangements, a relevant solution could be to implement the W3C’s Data Privacy Vocabulary that enables the expression of machine-readable metadata about the use and processing of personal data based on legislative requirements such as the GDPR. More details about the W3C Standards/Credentials can be found in the Identity and Attestation Management building block. Special categories of personal data (“sensitive” data)According to art. 9 (1) GDPR, personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, trade-union membership, genetic data, biometric data processed solely to identify a human being, health-related data, data concerning a person’s sex life or sexual orientation, shall be considered special categories of personal data, the processing of which is generally prohibited, unless one of the strictly enumerated legal bases set out in paragraph (2) occurs. They shall be strictly interpreted and considered separately for each processing activity.If one of the legal bases is applicable, it is important to remember that processing of such data still needs to be compliant with the principles, rights and obligations established in the GDPR. As indicated by the Spanish Data Protection Authority, in the case of processing of these data, it should be demonstrated that the conditions for lifting the prohibition of such processing set out in Article 9(2) of the GDPR are met. Processing special categories of data referred to in Article 9(2)(g) (essential public interest), (h) (purposes of preventive or occupational medicine, assessment of the worker’s capacity to work, medical diagnosis, provision of health or social care or treatment, or management of health and social care systems and services) and (i) (public interest in the field of public health) of the GDPR has to provide appropriate safeguards and has to be covered by a regulation having the force of law.The GDPR also requires assessing the following: The necessity of processing the data (This also includes appropriateness. For example, when processing is necessary to protect the data subject's vital interests or for reasons of substantial public interest based on Union or Member State law).The proportionality of the processing (for example, when data is processed under essential public interest, archiving purposes in the public interest, scientific or historical research purposes, or statistical purposes).Whether the processing activity can be considered “high-risk processing” or not. If this is the case, there must be an appropriate data protection impact assessment that will manage the high risk and demonstrates passing the assessment of necessity, appropriateness and strict proportionality.One of the types of sensitive data is biometric data. Biometric data can allow for the authentication, identification or categorisation of natural persons and for the recognition of emotions of natural persons. It is defined in Art. 4 (14) GDPR as personal data resulting from specific technical processing relating to the physical, physiological or behavioural characteristics of a natural person, which allow or confirm the unique identification of that natural person, such as facial images or dactyloscopic data. As it’s considered one of the special categories of data under GDPR, the processing of biometric data is prohibited in principle, providing only a limited number of conditions for the lawful processing of such data. Due to the increased use of biometric data in AI development and the immutability of physiological traits, the AI Act regulates the use of such data. In accordance with the AI Act, AI systems used for biometric categorisation based on sensitive attributes (protected under Article 9(1) GDPR) and emotion recognition should be classified as high-risk, in so far as these are not prohibited under this regulation. Biometric systems which are intended to be used solely for the purpose of enabling cybersecurity and personal data protection measures should not be considered high-risk AI systems. |
| Personal Data
Source (vsn) : Regulatory Compliance (bv20)
|
any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person;( GDPR Article 4(1) ) |
| Personal Data Access
Source (vsn) : Access & Usage Policies Enforcement (bv20)
|
Covers the necessary aspects regarding personal data access and consent. |
| Personal Data Intermediary
Source (vsn) : 4 Data Space Services (bv20)
|
A specific participant agent intermediary that is focused on providing services for natural persons. |
| Pilot
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
A planned and resourced implementation of one or more use cases within the context of a data space initiative. A data space pilot aims to validate the approach for a full data space deployment and showcase the benefits of participating in the data space.
Note : This term was automatically generated as a synonym for: data-space-pilot
|
| Policy
Source (vsn) : Access & Usage Policies Enforcement (bv30)
|
A machine-readable rule that expresses permissions, prohibitions, or obligations regarding data access and usage. Policies are encoded in ODRL and implement the terms and conditions defined in data product contracts.
See 3.4.2.1 Data product contract in Contractual Framework building block. |
| Policy Definition Language
Source (vsn) : 6 Data Policies and Contracts (bv30)
|
A machine-processable mechanism for representing statements about the data policies, e.g., Open Digital Rights Language (ODRL) |
| Policy Negotiation
Source (vsn) : Access & Usage Policies Enforcement (bv20)
|
The support and enforcement of policy negotiation among participants in their business operations and data transactions occurring in Data Spaces. |
| Policy Negotiation
Source (vsn) : Access & Usage Policies Enforcement (bv30)
|
The process through which a data provider and consumer agree on machine-readable policies for data sharing. The provider offers policies, the consumer may propose alternatives, resulting in a mutually acceptable data product contract. |
| Policy Validation
Sources (vsn) :
- Access & Usage Policies Enforcement (bv20)
- Access & Usage Policies Enforcement (bv30)
|
The process of verifying that policies are correctly structured, consistent, and free from conflicts. |
| Preparatory Stage
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
The stage in the development cycle that starts when a data space initiative has a critical mass of committed stakeholders and there is an agreement to move forward with the initiative and proceed towards creating a data space. It is typical for this stage that such partners jointly develop use cases and prepare to implement the data space. |
| Principles, Scope, Objectives (1)
Source (vsn) : Examples (bv20)
|
Principles:Sovereignty: self-determination of who will receive dataSafe exchange of dataIncreased efficiency in supply chainsScope:Supply chain in the manufacturing industryInvoice, order, product information dataObjectives:20% higher productivity of the supply chain by fast, safe, and interoperable exchange of informationExpand both horizontally and vertically in the value chain, initially on a European ScaleNo profit ambitions for the SCSN foundation |
| Provenance
Source (vsn) : Provenance, Traceability & Observability (bv30)
|
The place of origin or earliest known history of something. Usually it is the backwards-looking direction of a data value chain which is also referred to as provenance tracking |
| Provenance Traceability
Source (vsn) : Provenance & Traceability (bv20)
|
Any traceability data used to determine the provenance |
| Public Sector Bodies
Source (vsn) : Types of Participants (Participant as a Trigger) (bv20)
|
Public sector bodies perform legally defined duties for the benefit of the public interest. They can be subject to specific obligations to share certain categories of data, not only with data space participants but with other potential users outside of the data space as well. The data held by public sector bodies can be of structural relevance for a data space ecosystem. |
| Public Sector Body
Source (vsn) : Regulatory Compliance (bv20)
|
the State, regional or local authorities, bodies governed by public law or associations formed by one or more such authorities, or one or more such bodies governed by public law (art. 2 (17) DGA). |
| Pull Transfer
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
A data transfer initiated by the consumer, where data is retrieved from the provider. |
| Push Transfer
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
A data transfer initiated by the provider, where data is sent to the consumer. |
| Reference Datasets
Source (vsn) : Data Models (bv20)
|
Reference data, such as code lists and authority tables, means data that are used to characterise or relate to other data. Such a reference data, defines the permissible values to be used in a specific field for example as metadata. Reference data vocabularies are fundamental building blocks of most information systems. Using common interoperable reference data is essential for achieving interoperability. |
| Reference Datasets
Source (vsn) : Data Models (bv30)
|
Reference data, such as code lists and authority tables, means data that are used to characterise or relate to other data. Such a reference data, defines the permissible values to be used in a specific field for example as metadata. Reference data vocabularies are fundamental building blocks of most information systems. Using common interoperable reference data is essential for achieving interoperability.
|
| Refining Use Case Scenarios
Source (vsn) : Use Case Development (bv20)
|
Refining the description and design of use case scenarios using templates like the Data Cooperation Canvas, Use Case Playbook, or self created templates. |
| Refining Use Case Scenarios
Source (vsn) : Use Case Development (bv30)
|
Refining the description and design of use case scenarios using templates like the Data Cooperation Canvas, Use Case Playbook, or self-created templates. |
| Related Service
Source (vsn) : Regulatory Compliance (bv20)
|
means a digital service, other than an electronic communications service, including software, which is connected with the product at the time of the purchase, rent or lease in such a way that its absence would prevent the connected product from performing one or more of its functions, or which is subsequently connected to the product by the manufacturer or a third party to add to, update or adapt the functions of the connected product (art. 2 (6) DA).
Explanatory Text : This term is defined as per the Data Act. This clarification ensures that the definition is understood within the specific regulatory context of the Data Act while allowing the same term to be used in other contexts with different meanings.
|
| Relationship Manager
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A person from the Data Spaces Support Centre who serves as the dedicated DSSC contact point for a data space initiative or another member of the community of practice. |
| Research Data
Source (vsn) : Regulatory Compliance (bv20)
|
documents in a digital form, other than scientific publications, which are collected or produced in the course of scientific research activities and are used as evidence in the research process, or are commonly accepted in the research community as necessary to validate research findings and results (art. 2 (9) PSI Directive). |
| Researchers
Source (vsn) : Types of Participants (Participant as a Trigger) (bv20)
|
Researchers may join data spaces to make better use of their rights under legal frameworks, leveraging the EU legal frameworks that facilitate data access and explore how data spaces can enhance access and sharing of data. In the data-sharing context, they can be both data recipients and data providers. Researchers in the EU benefit from a number of legal frameworks that facilitate access to data, including provisions in the Open Data Directive that promote the re-use of public sector information. In addition, research exceptions in intellectual property law, such as the text and data mining exception of Art. 3 Copyright in the Digital Single Market Directive, and recently introduced measures such as Art. 40 of the Digital Services Act, introduce greater access to data for researchers (under specific circumstances mentioned in the Art. 8 DSA, and purposes of, among other things, detection, identification and understanding of systemic risks and assessment of their risk mitigation). The European Data Strategy and the creation of common data spaces demonstrate general mechanisms for increased data sharing and opening up privately-held data, including for researchers. Initiatives such as Horizon Europe further support open science and data sharing, and guidelines for ethical data management and sharing agreements foster a supportive scientific research and innovation environment.For a comprehensive analysis, see: https://data.europa.eu/doi/10.2777/633395 |
| Revenue And Pricing (for Use Cases, Data Providers, Data Recipients) (5b)
Source (vsn) : Examples (bv20)
|
Use case participants pay fees to service providers, not directly to the data space. The participants usually already have a service contract with the service providers for use of their private platforms. |
| Revenue And Pricing (to Service Providers) (5b)
Source (vsn) : Examples (bv20)
|
SCSN foundation gets a predetermined fixed contribution per service provider. The contribution depends on the number of connected users.The governance authority (SCSN Foundation) gets a fixed amount of money from the service providers for connection to the network, which is amended by a fee per end user.The end-users pay the service providers, who set their own prices for the end-users. |
| Rulebook
Source (vsn) : 1 Key Concept Definitions (bv30)
|
The documentation of the data space governance framework for operational use.
Explanatory Text : The rulebook can be expressed in human-readable and machine-readable formats.
Note : This term was automatically generated as a synonym for: data-space-rulebook
|
| Scalability
Source (vsn) : Value creation services (bv20)
|
Elastic access to compute resources, that enable their dynamically allocation Consider at governance / legal level to include auto-scaling policies, that based on metrics can automatically adjust resource allocation and service usageResource quotas to ensure fair distribution of resources and use of services |
| Scaling Stage
Source (vsn) : 3 Evolution of Data Space Initiatives (bv30)
|
The stage in the development cycle that starts when a data space initiative has been proven to consistently and organically gain new participants and embrace new use cases. In this stage, the data space can realistically be expected to be financially and operationally sustainable, respond to market changes, and grow over time. |
| Scope Of Attestation
Source (vsn) : Identity & Attestation Management (bv30)
|
range or characteristics of objects of conformity assessment covered by attestation . |
| Second-party Conformity Assessment Activity
Source (vsn) : Identity & Attestation Management (bv30)
|
conformity assessment activity that is performed by a person or organization that has a user interest in the object of conformity assessment (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Security
Source (vsn) : Value creation services (bv20)
|
Align with authentication mechanisms of the data space and the service itself to secure service access.Include security audits and vulnerability assessmentsEnsure data at rest and in motion is encryptedImplement necessary controls |
| Service Description
Sources (vsn) :
- Data, Services, and Offerings Descriptions (bv20)
- Data, Services, and Offerings Descriptions (bv30)
|
A service description is composed of attributes related to data services, including endpoint description and endpoint URL. Additionally, it may encompass a wide range of attributes related to value-added technical- and support services such as software-, platform-, infrastructure-, security-, communication-, and managed services. These services are used for various purposes, such as data quality, analysis, and visualisation. |
| Service Offering Credential
Source (vsn) : Identity & Attestation Management (bv30)
|
A service description that follows the schemas defined by the Data Space Governance Authority and whose claims are validated by the Data Space Compliance Service.
Note : This term was automatically generated as a synonym for: data-space-service-offering-credential
|
| Services
Sources (vsn) :
- 1 Key Concept Definitions (bv30)
- 4 Data Space Services (bv30)
|
Functionalities for implementing data space capabilities, offered to participants of data spaces.
Explanatory Texts :
- We distinguish three classes of technical services which are further defined in section 4 of this glossary: Participant Agent Services, Facilitating Services, Value-Creation Services. Technical (software) components are needed to implement these services.
- Also on the business and organisational side, services may exist to support participants and orchestrators of data spaces, further defined in section 4 of this glossary and discussed in the Business and Organisational building blocks introduction.
- Please note that a Data Service is a specific type of service related to the data space offering, providing access to one or more datasets or data processing functions.
Note : This term was automatically generated as a synonym for: data-space-services
|
| Services And Providers (3)
Source (vsn) : Examples (bv20)
|
On behalf of the SCSN foundation, the executive body of the governance authority arranges for a broker service and identity provisioning (which is outsourced to KPN). This service provider also provides a vocabulary hub in which the data model is specified. Service providers provide services and platforms to parts of the supply chains. |
| Services Management
Source (vsn) : Value creation services (bv20)
|
Dedicated services registry as part of the general data space registry / data space wallet Connection with data space catalogue, to enable mechanisms to register and locate services, with detailed descriptions, usage instructions, and access policies. Use specific tools for services orchestration to manage the deployment, scaling, and operation of services, and for load balancing Implement workflow automation tools to coordinate complex service interactions.Include alerting systems to notify administrators of service issues or performance degradationApply tools like service mesh or dependency graphs to manage dependencies and relationships between services |
| Services Provisioning And Delivery
Source (vsn) : Value creation services (bv20)
|
Depending on the requirements and storage resources in the data space, consider the containerization of services for their provisioning and deployment, to ensure portability, scalability, and resource efficiency.API gateway, to implement client requests to services. To consider if those requests can be included in the data plane of the data spaceArtifact repository, to store, manage, and distribute the services, to facilitate version control, dependency management, and services retrieval. |
| Smart Contract
Source (vsn) : Contractual Framework (bv30)
|
A computer program used for the automated execution of an agreement or part thereof, using a sequence of electronic data records and ensuring their integrity and the accuracy of their chronological ordering (Art 2(39) Data Act)
|
| Stakeholders (4)
Source (vsn) : Examples (bv20)
|
Over time, SCSN has received support from stakeholders such as the regional development agency (BOM), the province of Noord-Brabant, the European Commission, and the cooperative Brainport Industry Campus. |
| Starter Kit
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A document that helps organisations and individuals in the network of stakeholders to understand the requirements for creating a data space.
Note : This term was automatically generated as a synonym for: data-spaces-starter-kit
|
| Strategic Stakeholder Forum
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
The designated group of experts that provide strategic support for the DSSC and make recommendations for the governance and sustainability of the DSSC assets. The strategic stakeholder forum is composed of a large variety of stakeholders with a balanced geographical distribution and will evolve progressively. |
| Subject
Source (vsn) : Identity & Attestation Management (bv30)
|
thing about which claims are made (ref. Verifiable Credentials Data Model v2.0 (w3.org) ) |
| Sui Generis Database Right
Source (vsn) : Regulatory Compliance (bv20)
|
right for the maker of a database which shows that there has been qualitatively and/or quantitatively a substantial investment in either the obtaining, verification or presentation of the contents to prevent extraction and/or re-utilization of the whole or of a substantial part, evaluated qualitatively and/or quantitatively, of the contents of that database (art. 7 Directive 96/9/EC Of The European Parliament And Of The Council of 11 March 1996 on the legal protection of databases). |
| Support Organisation
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
An organisation, consortium, or collaboration network that specifies architectures and frameworks to support data space initiatives. Examples include Gaia-X, IDSA, FIWARE, iSHARE, MyData, BDVA, and more.
Note : This term was automatically generated as a synonym for: data-space-support-organisation
|
| Synergy Between Data Spaces
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
The gained efficiency, increased impact or other benefits of two or more data spaces working together that are greater than if the data spaces were working separately. The synergies between data spaces can be enabled by common practices, communication concepts, services and/or components, which increase data space interoperability and enable harmonised processes of using different data spaces. |
| Technology Landscape
Source (vsn) : 10 DSSC Specific Terms (bv30)
|
A repository of standards (de facto and de jure), specifications and open-source reference implementations available for deploying data spaces. The Data Space Support Centre curates the repository and publishes it with the blueprint.
Note : This term was automatically generated as a synonym for: data-spaces-technology-landscape
|
| Third-party Conformity Assessment Activity
Source (vsn) : Identity & Attestation Management (bv30)
|
conformity assessment activity that is performed by a person or organization that is independent of the provider of the object of conformity assessment and has no user interest in the object (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Traceability
Source (vsn) : Provenance, Traceability & Observability (bv30)
|
The quality of having an origin or course of development that may be found or followed |
| Trade Secret
Source (vsn) : Regulatory Compliance (bv20)
|
information which meets all of the following requirements:
it is secret in the sense that it is not, as a body or in the precise configuration and assembly of its components, generally known among or readily accessible to persons within the circles that normally deal with the kind of information in question;it has commercial value because it is secret;it has been subject to reasonable steps under the circumstances, by the person lawfully in control of the information, to keep it secret. (art. 2 (1) Trade Secrets Directive).
|
| Transfer Process (TP)
Sources (vsn) :
- Data Exchange (bv20)
- Data Exchange_ (bv30)
|
A process that manages the lifecycle of data exchange between a provider and a consumer, involving, in example, states, as a minimum, REQUESTED, STARTED, COMPLETED, SUSPENDED, and TERMINATED. |
| Trigger
Source (vsn) : Regulatory Compliance (bv20)
|
An element, criteria or an event that has occurred in a particular context of a data space, that signals that a particular legal framework must or should be applied. |
| Trust Anchor
Source (vsn) : 8 Identity and Trust (bv20)
|
Trust Anchors are bodies, parties, i.e., Conformity Assessment Bodies or technical means accredited by the data space governance authority to be parties eligible to issue attestations about specific claims. |
| Trust Anchor
Source (vsn) : 8 Identity and Trust (bv30)
|
An authoritative entity for which trust is assumed and not derived. Each Trust Anchor is accepted by the data space governance authority in relation to a specific scope of attestation . |
| Trust Anchor
Source (vsn) : Trust Framework (bv30)
|
An entity for which trust is assumed and not derived. Each Trust Anchor is accepted by the data space governance authority in relation to a specific scope of attestation . |
| Trust Decision
Sources (vsn) :
- 8 Identity and Trust (bv20)
- 8 Identity and Trust (bv30)
|
A judgement made by a party to rely on some statement being true without requiring absolute proof or certainty. |
| Trust Framework
Sources (vsn) :
- 8 Identity and Trust (bv20)
- 8 Identity and Trust (bv30)
|
A composition of policies, rules, standards, and procedures designed for trust decisions in data spaces based on assurances. Trust framework is part of the data space governance framework. |
| Trust Framework
Source (vsn) : Trust Framework (bv30)
|
A trust framework is comprised of:(business-related) policies, rules, and standards collected and documented in the rulebook.procedures for automation and implementation of the business-related components. |
| Trust Service
Source (vsn) : Access & Usage Policies Enforcement (bv30)
|
A service that verifies claims used in policy evaluation (e.g., participant credentials, certifications). Examples include identity providers and credential verification services. |
| Trust Service Provider
Source (vsn) : Trust Framework (bv30)
|
Trust Service Providers (also referred to as Trusted Issuers) are legal or natural persons deriving their trust from one or more Trust Anchors and designated by the data space governance authority as parties eligible to issue attestations about specific objects. |
| Trusted Data Source
Source (vsn) : Trust Framework (bv30)
|
Source of the information used by the issuer to validate attestations. The data space defines the list of Trusted Data Sources for the Data Space Conformity Assessment Scheme/s. |
| Trusted Execution
Source (vsn) : Value creation services (bv20)
|
Allign with the trust framework of the data space, and on its capabilities to identify, autenticate and authorize usersEnsure, for the execution, compliance with the data space rulebook and existing regulationsIf required and possible, consider the use of hardware-based Trusted Execution Environments (TEE), to ensure that code and data are protected during execution, and / or virtualization based security tools. |
| Usage Control
Sources (vsn) :
- Access & Usage Policies Enforcement (bv20)
- Access & Usage Policies Enforcement (bv30)
|
Mechanisms that specify and enforce how data can be used after access has been granted. |
| Use Case
Source (vsn) : 1 Key Concept Definitions (bv30)
|
A specific setting in which two or more participants use a data space to create value (business, societal or environmental) from data sharing.
Explanatory Texts :
- By definition, a data space use case is operational. When referring to a planned or envisioned setting that is not yet operational we can use the term use case scenario.
- Use case scenario is a potential use case envisaged to solve societal, environmental or business challenges and create value. The same use case scenario, or variations of it, can be implemented as a use case multiple times in one or more data spaces.
Note : This term was automatically generated as a synonym for: data-space-use-case
|
| Use Case Development
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
A strategic approach to amplify the value of a data space by fostering the creation, support and scaling of use cases. |
| Use Case Orchestrator
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
A data space participant that represents and is accountable for a specific use case in the context of the governance framework. The orchestrator establishes and enforces business rules and other conditions to be followed by the use case participants. [role] |
| Use Case Participant
Source (vsn) : 2 Data Space Use Cases and Business Model (bv30)
|
A data space participant that is engaged with a specific use case. [role] |
| Use Cases, Data Providers And Data Users (2)
Source (vsn) : Examples (bv20)
|
One use case currently: Connecting ERP and other order systems to create efficient and robust supply chains. This leads to a reduction in administrative costs and a reduction in human error while sending and processing orders.Interoperability is established through a jointly developed standard. According to its foundational documents, maintenance of this standard is the core task of the SCSN foundation.
Future use cases: price updates, stock information, and others. |
| Validation
Sources (vsn) :
- 8 Identity and Trust (bv20)
- 8 Identity and Trust (bv30)
- Identity & Attestation Management (bv30)
|
Confirmation of plausibility for a specific intended use or application through the provision of objective evidence that specified requirements have been fulfilled (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Value Creation Services
Source (vsn) : Value creation services (bv30)
|
(technical) elements or components designed to unlock, generate and maximize the value of data shared within a data space, providing additional functionalities on top of the core process of data sharing or data transaction.
Explanatory Texts :
- This value is delivered both for (i) data space participants (by enabling services and applications that operate on top of data exchanges and transactions), and (ii) for the data space itself (supporting and enhancing core functionalities, such as semantic interoperability, data quality, discoverability, trust mechanisms and others)
- Value creation services act over data products, and are combined with them in data space offerings, to perfom the functionalities required by the defined use cases.
- Value creation services complement the capabilities provided by the “federation services” and the “participant agent” services
- This value creation can come from different sides: complementing the essential capabilities of the data space, acting directly over datasets that these services are tied to, as part of data products, adding value on top of data products and data transactions, enabling the connection to external infrastructures, required to, among others, process, store and collect data, either as part of the normal operation of the data space or as needed by some use cases, enabling the connection to external applications, which are required for the complete development of use cases, facilitating by any other means the materialization of the business models considered in the data space.
|
| Value Proposition
Source (vsn) : Business Model (bv30)
|
A value proposition reflects the benefits for a segment of customers when adopting an offer.Benefits are typically associated with so-called pains and gains and are, therefore, fundamentally linked to key customer processes. In the case of a data space, a lack of control by data owners (sovereignty) represents one potential pain; other pains include the inaccessibility of data and non-interoperable data sources, which drive up the costs of innovative data-driven applications. |
| Value Proposition To Service Providers (5)
Source (vsn) : Examples (bv20)
|
Each service provider has their own client base that could be of value to the network. It is important to note that purely having a number of clients does not mean they are automatically connected to the SCSN data space. The service providers themselves add SCSN to their existing services. |
| Value Proposition To Use Cases, Data Providers And Data Recipients (5)
Source (vsn) : Examples (bv20)
|
Choices for the development agenda are made in conjunction with service providers. (In the context of SCSN, the term service provider refers to the role of an intermediary that connects some of its customers to the SCSN network.) These service providers have discussions with their clients (the data space participants). There is, however, no formal power for service providers to vote on the type of use case that needs to be developed. Functionality for users of the proprietary platform of the service provider is typically more extensive than functionality related to users of interoperable platforms. This allows service providers to focus on specific niches and capture value while establishing interoperability with co-competing service providers. |
| Value-creation Service
Source (vsn) : 4 Data Space Services (bv20)
|
Any service aimed to create value out of the data shared in the data space.
Explanatory Texts :
- Value creation services complement the capabilities provided by the “federation services” and the “participant agent” services
- This value creation can come from different sides: complementing the essential capabilities of the data space, acting directly over datasets that these services are tied to, as part of data products, adding value on top of data products and data transactions, enabling the connection to external infrastructures, required to, among others, process, store and collect data, either as part of the normal operation of the data space or as needed by some use cases, enabling the connection to external applications, which are required for the complete development of use cases, facilitating by any other means the materialisation of the business models considered in the data space.
|
| Value-creation Services
Source (vsn) : 4 Data Space Services (bv30)
|
(Technical) elements or components designed to unlock, generate and maximize the value of data shared within a data space, providing additional functionalities on top of the core process of data sharing or data transaction.
Explanatory Texts :
- This value is delivered both for (i) data space participants (by enabling services and applications that operate on top of data exchanges and transactions), and (ii) for the data space itself (supporting and enhancing core functionalities, such as semantic interoperability, data quality, discoverability, trust mechanisms and others)
- Value creation services act over data products, and are combined with them in data space offerings, to perfom the functionalities required by the defined use cases.
- Value creation services complement the capabilities provided by the “federation services” and the “participant agent” services
- This value creation can come from different sides: complementing the essential capabilities of the data space, acting directly over datasets that these services are tied to, as part of data products, adding value on top of data products and data transactions, enabling the connection to external infrastructures, required to, among others, process, store and collect data, either as part of the normal operation of the data space or as needed by some use cases, enabling the connection to external applications, which are required for the complete development of use cases, facilitating by any other means the materialization of the business models considered in the data space.
|
| Verifiable Credential
Sources (vsn) :
- Identity & Attestation Management (bv30)
- Trust Framework (bv30)
|
A verifiable credential is a tamper-evident credential that has authorship that can be cryptographically verified. Verifiable credentials can be used to build verifiable presentations , which can also be cryptographically verified (ref. https://www.w3.org/TR/vc-data-model-2.0/#dfn-verifiable-credential ) |
| Verifiable ID
Source (vsn) : Identity & Attestation Management (bv30)
|
It refers to a type of Verifiable Credential that a natural person or legal entity can use to demonstrate who they are. This verifiableID can be used for Identification and Authentication. (ref. Verifiable Attestation for ID - EBSI Specifications - ( http://europa.eu/ )) |
| Verifiable Presentation
Source (vsn) : Identity & Attestation Management (bv30)
|
A tamper-evident presentation of information encoded in such a way that authorship of the data can be trusted after a process of cryptographic verification. Certain types of verifiable presentations might contain data that is synthesized from, but does not contain, the original verifiable credentials (for example, zero-knowledge proofs). (ref. Verifiable Credentials Data Model v2.0 (w3.org) ) |
| Verification
Sources (vsn) :
- 8 Identity and Trust (bv20)
- 8 Identity and Trust (bv30)
- Identity & Attestation Management (bv30)
|
Confirmation of truthfulness through the provision of objective evidence that specified requirements have been fulfilled (ref. ISO/IEC 17000:2020(en), Conformity assessment — Vocabulary and general principles ) |
| Verifier
Source (vsn) : Identity & Attestation Management (bv30)
|
A role an entity performs by receiving one or more verifiable credentials , optionally inside a verifiable presentation for processing. Other specifications might refer to this concept as a relying party. (ref. Verifiable Credentials Data Model v2.0 (w3.org) ) |
| Vocabulary
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A data model that contains basic concepts and relationships expressed as terms and definitions within a domain or across domains, typically described in a meta-standard like SKOS. |
| Vocabulary Service
Sources (vsn) :
- Data Models (bv20)
- Data Models (bv30)
|
A technical component providing facilities for publishing, editing, browsing and maintaining vocabularies and related documentation. |